Uploading and editing a file
| 🌐 This document is available in both English and Ukrainian. Use the language toggle in the top right corner to switch between versions. |
The Platform team developed the reference examples of regulations modeling that can help developers to understand better the specifics of interaction with the system when working with digital documents.
1. Preconditions
-
Use the reference examples of regulations modeling.
Examples of reference business process diagrams and UI forms are available in the demo registry regulations under the corresponding names with the
reference-prefix:-
reference-upload-update-digital-document.bpmn
-
reference-digital-document-upload.json
-
reference-digital-document-edit.json
-
reference-digital-document-review.json
Visit the Deploying demo registry with reference examples page to learn how to deploy a demo registry and get reference examples of regulations modeling. -
-
Model the Liquibase changeset to create the
parent_datatable according to your logical data model. In our reference example, the following logical model is used:- The Liquibase template of the physical model will look as follows:
-
Creating the parent_data table
<changeSet id="create_table_parent_data" author="your_author_name"> <comment>CREATE TABLE parent_data</comment> <createTable tableName="parent_data" ext:historyFlag="true"> <column name="id" type="UUID"> <constraints nullable="false" primaryKey="true" primaryKeyName="pk_parent_data"/> </column> <column name="parent_full_name" type="TEXT"> <constraints nullable="false"/> </column> <column name="phone_number" type="TEXT"> <constraints nullable="false"/> </column> <column name="additional_phone_number" type="TEXT"/> </createTable> </changeSet>For more information on creating registry data model tables and other tags, see Liquibase extensions for data modeling.
-
Prepare the corresponding CSV file for uploading to the system.
Example of the CSV file content containing one recordparents_full_name;phone_number;additional_phone_number Bruce Don Walker;38(000)111 11 11;
The initial table filling with data uses the PL/pgSQL database procedure.
-
For a detailed description of the procedure on the initial data loading, read the Initial loading of registry data page.
-
Also see Task 1. Modeling registry database structures for practical application of the initial loading when modeling the regulations.
-
-
Model your own business process using the following example.
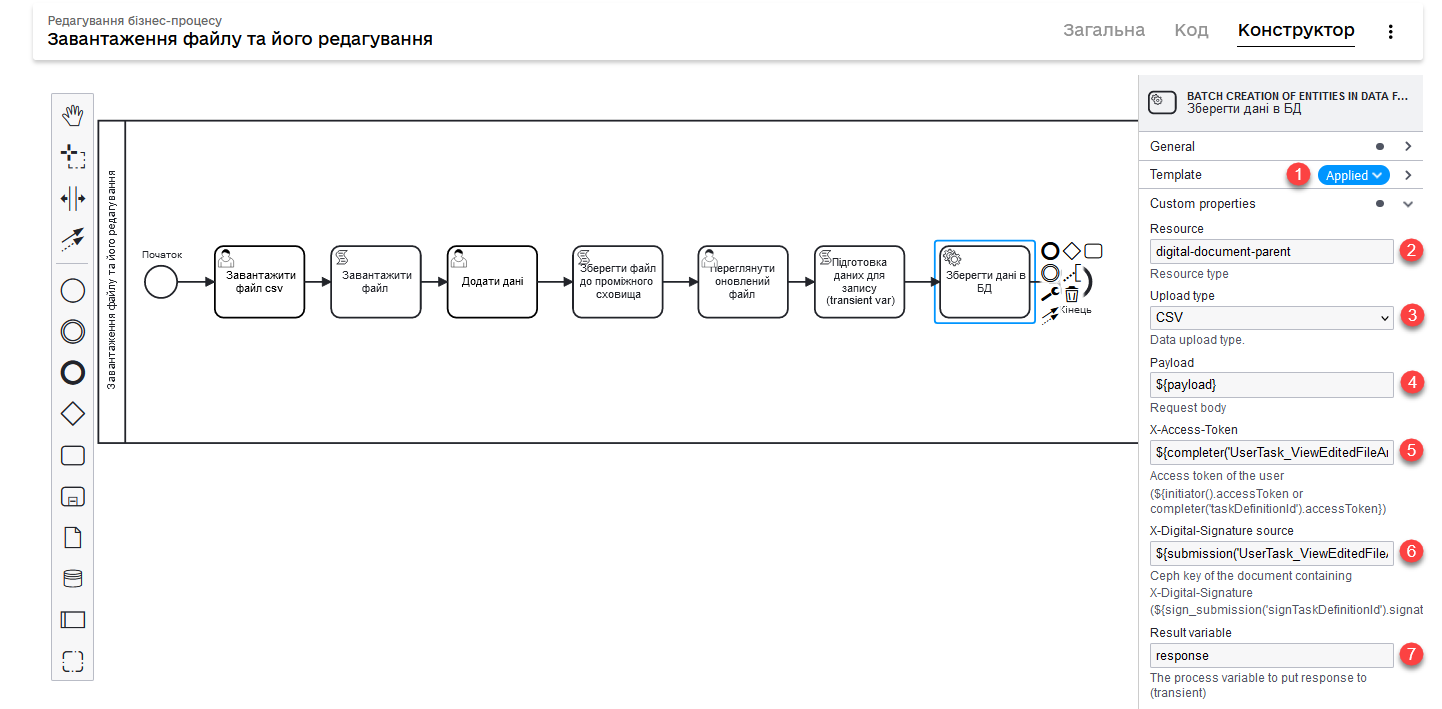
2. Business Process Modeling
-
Simulate the User Task and the corresponding UI form using which you can download prepared files. In our example, that is
CSV.You can learn more about uploading digital documents on the business process forms on the page Loading multiple files in one field using the File component.
Pass the file parameter to the script task for further processing.
-
Model the Script Task and generate a script for processing, loading, and retrieving the metadata of a digital document. For that, the script uses two JUEL functions:
- Let’s take a closer look at the Groovy script. You can view it in the script editor for script tasks:
Details
def file = submission('UserTask_AddDocument').formData.prop('file').elements().get(0)
def id = file.prop('id').value();
def document = load_digital_document(id)
def originalMetadata = get_digital_document_metadata(id)
def csvData = new String(document, 'UTF-8')
if (csvData.startsWith("\ufeff")) {
csvData = csvData.substring(1)
}
def records = csvData.readLines()
def headers = records[0].split(';')
set_variable("originalHeaders", headers)
def jsonData = []
for (int i = 1; i < records.size(); i++) {
def record = records[i].split(';', -1)
def recordData = [:]
for (int j = 0; j < headers.size(); j++) {
recordData[headers[j]] = record[j]
}
jsonData.add(recordData)
}
def output = [:]
output['csvFile'] = jsonData
set_variable('originalMetadata', S(originalMetadata, 'application/json'))
set_variable('csvFile', S(output, 'application/json'))This script processes the CSV file that the user adds using the UserTask_AddDocument task. Let’s see how it works:
-
The script first receives a file with data that the user downloaded in the UI form of the portal:
def file = submission('UserTask_AddDocument').formData.prop('file').elements().get(0) def id = file.prop('id').value(); -
Then the
load_digital_document(id)function is used to load a digital document with the specified ID, and we also get the metadata of this document:def document = load_digital_document(id) def originalMetadata = get_digital_document_metadata(id) -
The digital document we receive is converted from bytes to a string using the
UTF-8encoding. If the string starts withBOM(byte order mark), it is deleted:def csvData = new String(document, 'UTF-8') if (csvData.startsWith("\ufeff")) { csvData = csvData.substring(1) } -
Data from the CSV file is read line by line. The first line contains headers that are stored into the variable:
def records = csvData.readLines() def headers = records[0].split(';') -
Then the script goes through each line of the CSV file (except the first line), divides the line into separate values using the
;separator and creates an associative array (map), where the keys correspond to CSV headers, and the values correspond to the specific values in the line. All these associative arrays are compiled into the list:def jsonData = [] for (int i = 1; i < records.size(); i++) { def record = records[i].split(';', -1) def recordData = [:] for (int j = 0; j < headers.size(); j++) { recordData[headers[j]] = record[j] } jsonData.add(recordData) } -
At the final stage, the script saves the original document metadata and processed CSV file data into the
originalMetadataandcsvFilevariables that can be used elsewhere in the business process:set_variable('originalMetadata', S(originalMetadata, 'application/json')) set_variable('csvFile', S(output, 'application/json'))
In the event that you receive a CSV file from a user and want to process it in a workflow, this script is a good example of how this can be done.
-
Pass the CSV file data to the next custom form. This can be done by entering in the Form data pre-population the
${csvFile}variable, obtained as a result of executing the Groovy script in a previous script task. This UI form involves editing the data of a digital document (here, entering the new data).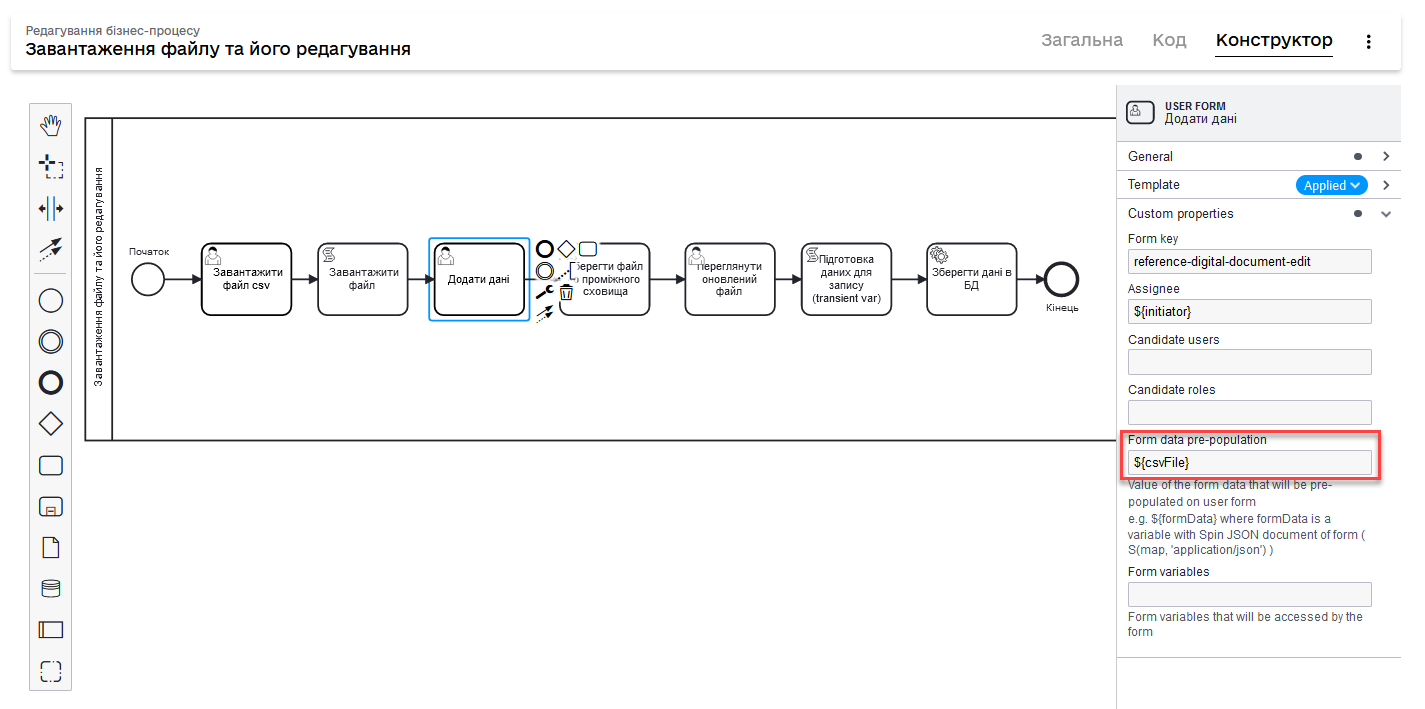
-
Model a Script Task and generate a script to save the digital document to an intermediate repository. To do this, the script uses the save_digital_document() JUEL function.
- Let’s take a closer look at the Groovy script. You can view it in the script editor for script tasks:
-
The script for saving a downloaded file to an intermediate data storage
import groovy.json.JsonSlurper def payload = submission('UserTask_EditDocumentData').formData.prop('csvFile').elements() def records = new JsonSlurper().parseText(payload.toString()) def csvData = "\uFEFF" + originalHeaders.join(';') records.each { record -> def values = originalHeaders.collect { header -> record.get(header) } def csvRow = values.join(';') csvData += '\n' + csvRow } def content = csvData.getBytes('UTF-8') def fileName = originalMetadata.prop('name').value() def metadata = save_digital_document(content, fileName) def result = [:] result['uploadedFile'] = [metadata] set_variable('result', S(result, 'application/json'))This Groovy script performs several steps, including:
-
It gets data from the form named
UserTask_EditDocumentData, which is a JSON object, and converts it into the Groovy object usingJsonSlurper.def payload = submission('UserTask_EditDocumentData').formData.prop('csvFile').elements() def records = new JsonSlurper().parseText(payload.toString()) -
It initiates the
csvDatavariable with the header values from the original file separated by the;symbol.def csvData = "\uFEFF" + originalHeaders.join(';') -
It sorts through the JSON records (which were CSV) and forms a CSV string for each record, adding it to
csvData.records.each { record -> def values = originalHeaders.collect { header -> record.get(header) } def csvRow = values.join(';') csvData += '\n' + csvRow } -
It converts
csvDatainto a byte array with theUTF-8encoding.def content = csvData.getBytes('UTF-8') -
It saves the updated document in the digital document service and retrieves the metadata of the document.
def fileName = originalMetadata.prop('name').value() def metadata = save_digital_document(content, fileName) -
It creates an object that contains the metadata of the loaded document and stores it in the
resultvariable of the process.def result = [:] result['uploadedFile'] = [metadata] set_variable('result', S(result, 'application/json'))Collectively, this script performs the task of converting the JSON format back to CSV, stores the updated CSV document in the digital document service, and stores the metadata of the new document into the process variable.
-
-
Similar to step 3, pass the data from the updated file to the UI form, but this time in the Form data pre-population field, enter the
${result}variable obtained in the previous script. This form will show you information about the file. -
Model a script task and use the script to prepare the data obtained from a digital document to be stored in the registry data storage.
set_transient_variable('payload', submission('UserTask_ViewEditedFileAndSign').formData.prop('uploadedFile').elements().first())The script receives data from the
UserTask_ViewEditedFileAndSigntask via thesubmission()function, processes it, and saves it to thepayloadtemporary variable using theset_transient_variable()function. -
Save the data to the permanent storage. To do this, create the Service Task and use the Batch creation of entities in data factory delegate.
The use of the delegate when loading files is described in detail here: Batch creation of entities in data factory v2.