Завантаження файлу та його редагування
| 🌐 Цей документ доступний українською та англійською мовами. Використовуйте перемикач у правому верхньому куті, щоб змінити версію. |
Команда Платформи розробила референтні приклади моделювання регламенту, які допоможуть розробникам краще розуміти специфіку взаємодії із системою при роботі із цифровими документами.
1. Передумови
-
Скористайтеся референтними прикладами моделювання регламенту.
Приклади схем референтного бізнес-процесу та UI-форм доступні у регламенті демо-реєстру за відповідними назвами із префіксом
reference-:-
reference-upload-update-digital-document.bpmn
-
reference-digital-document-upload.json
-
reference-digital-document-edit.json
-
reference-digital-document-review.json
Як розгорнути демо-реєстр та отримати референтні приклади моделювання регламенту, дивіться на сторінці Розгортання демо-реєстру із референтними прикладами. -
-
Змоделюйте Liquibase changeset для створення таблиці
parent_dataвідповідно до вашої логічної моделі даних. У нашому референтному прикладі використано наступну логічну модель:- Liquibase-шаблон фізичної моделі виглядатиме так:
-
Створення таблиці parent_data
<changeSet id="create_table_parent_data" author="your_author_name"> <comment>CREATE TABLE parent_data</comment> <createTable tableName="parent_data" ext:historyFlag="true"> <column name="id" type="UUID"> <constraints nullable="false" primaryKey="true" primaryKeyName="pk_parent_data"/> </column> <column name="parent_full_name" type="TEXT"> <constraints nullable="false"/> </column> <column name="phone_number" type="TEXT"> <constraints nullable="false"/> </column> <column name="additional_phone_number" type="TEXT"/> </createTable> </changeSet>Детальну інформацію про створення таблиць моделі даних реєстру та інші теги ви можете переглянути на сторінці Розширення Liquibase для моделювання даних.
-
Підготуйте відповідний CSV-файл до завантаження у систему.
Приклад вмісту CSV-файлу з одним записомparents_full_name;phone_number;additional_phone_number Сидоренко Іван Іванович;38(000)111 11 11;
Первинне наповнення таблиць даними відбувається за допомогою БД-процедури PL/pgSQL.
-
Детальний опис процедури для первинного завантаження даних читайте на сторінці Первинне завантаження даних реєстру (initial load).
-
Також перегляньте Завдання 1. Моделювання структур бази даних реєстру для ознайомлення із практичним застосуванням первинного завантаження при моделюванні регламенту.
-
-
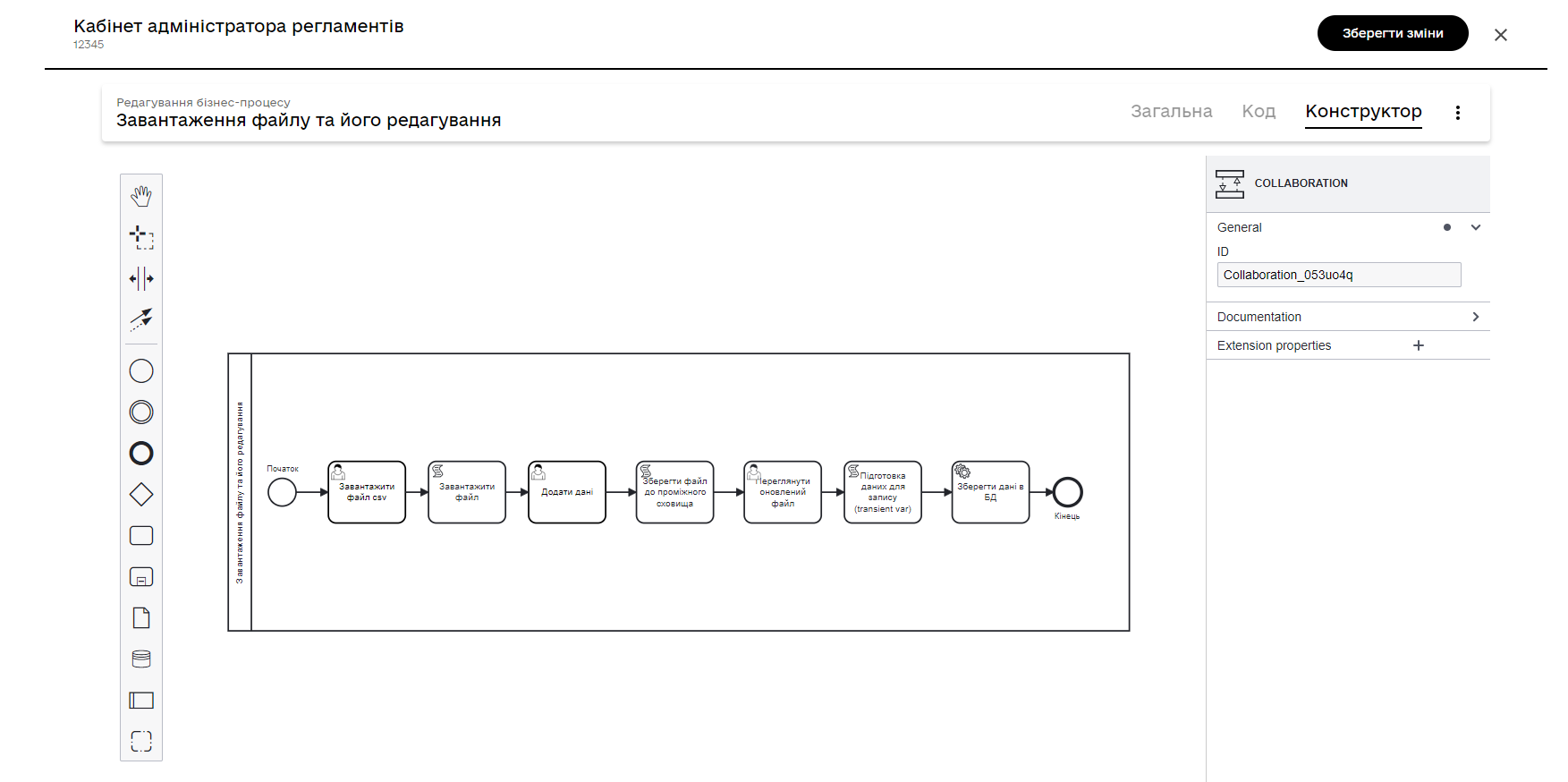
Змоделюйте власний бізнес-процес за наведеними прикладом.
2. Моделювання бізнес-процесу
-
Змоделюйте користувацьку задачу (User Task) та відповідну UI-форму, через яку ви зможете завантажувати підготовлені файли. У нашому прикладі — це
CSV.Детальніше про завантаження цифрових документів на формах бізнес-процесу ви можете ознайомитися на сторінці Завантаження масиву файлів в одному полі через компонент File.
Параметри з файлу передайте до скрипт-задачі для подальшої обробки.
-
Змоделюйте скрипт-задачу (Script Task) та сформуйте скрипт для обробки, завантаження та отримання метаданих цифрового документа. Для цього у скрипті використані дві JUEL-функції:
-
get_digital_document_metadata()
- Розглянемо більш детально Groovy-скрипт. Ви можете переглянути його у редакторі скриптів на скрипт-задачі:
-
Скрипт обробки CSV-файлу, який користувач додає через користувацьку задачу
def file = submission('UserTask_AddDocument').formData.prop('file').elements().get(0) def id = file.prop('id').value(); def document = load_digital_document(id) def originalMetadata = get_digital_document_metadata(id) def csvData = new String(document, 'UTF-8') if (csvData.startsWith("\ufeff")) { csvData = csvData.substring(1) } def records = csvData.readLines() def headers = records[0].split(';') set_variable("originalHeaders", headers) def jsonData = [] for (int i = 1; i < records.size(); i++) { def record = records[i].split(';', -1) def recordData = [:] for (int j = 0; j < headers.size(); j++) { recordData[headers[j]] = record[j] } jsonData.add(recordData) } def output = [:] output['csvFile'] = jsonData set_variable('originalMetadata', S(originalMetadata, 'application/json')) set_variable('csvFile', S(output, 'application/json'))Цей скрипт обробляє CSV-файл, який користувач додає через задачу
UserTask_AddDocument. Розгляньмо, як він працює:-
Скрипт спочатку отримує файл із даними, який користувач завантажив на UI-формі Кабінету:
def file = submission('UserTask_AddDocument').formData.prop('file').elements().get(0) def id = file.prop('id').value(); -
Потім використовується функція
load_digital_document(id), щоб завантажити цифровий документ зі вказаним ID, а також отримуємо метадані цього документа:def document = load_digital_document(id) def originalMetadata = get_digital_document_metadata(id) -
Цифровий документ, який ми отримали, перетворюється з байтів у рядок (стрічку) з використанням кодування
UTF-8. Якщо стрічка починається зBOM(позначка порядку байтів), вона видаляється:def csvData = new String(document, 'UTF-8') if (csvData.startsWith("\ufeff")) { csvData = csvData.substring(1) } -
Дані з CSV-файлу читаються рядок за рядком. Перший рядок містить заголовки, які зберігаються в змінну:
def records = csvData.readLines() def headers = records[0].split(';') -
Потім скрипт проходить по кожному рядку CSV-файлу (крім першого), ділить рядок на окремі значення за допомогою розділювача (
;) і створює асоціативний масив (map), де ключі відповідають заголовкам CSV, а значення — конкретним значенням в рядку. Всі ці асоціативні масиви збираються у список:def jsonData = [] for (int i = 1; i < records.size(); i++) { def record = records[i].split(';', -1) def recordData = [:] for (int j = 0; j < headers.size(); j++) { recordData[headers[j]] = record[j] } jsonData.add(recordData) } -
На завершальному етапі скрипт зберігає оригінальні метадані документа та оброблені дані CSV-файлу до змінних
originalMetadataтаcsvFile, які можуть використовуватися в інших місцях бізнес-процесу:set_variable('originalMetadata', S(originalMetadata, 'application/json')) set_variable('csvFile', S(output, 'application/json'))
У випадку, якщо ви отримуєте CSV-файл від користувача і хочете обробити його в робочому процесі, цей скрипт — хороший приклад того, як це можна зробити.
-
-
Передайте дані CSV-файлу до наступної користувацької форми. Зробити це можна, вказавши у полі Form data pre-population змінну
${csvFile}, отриману в результаті виконання Groovy-скрипту у попередній скриптовій задачі. Ця UI-форма передбачає редагування даних цифрового документа (тут — додавання нових даних).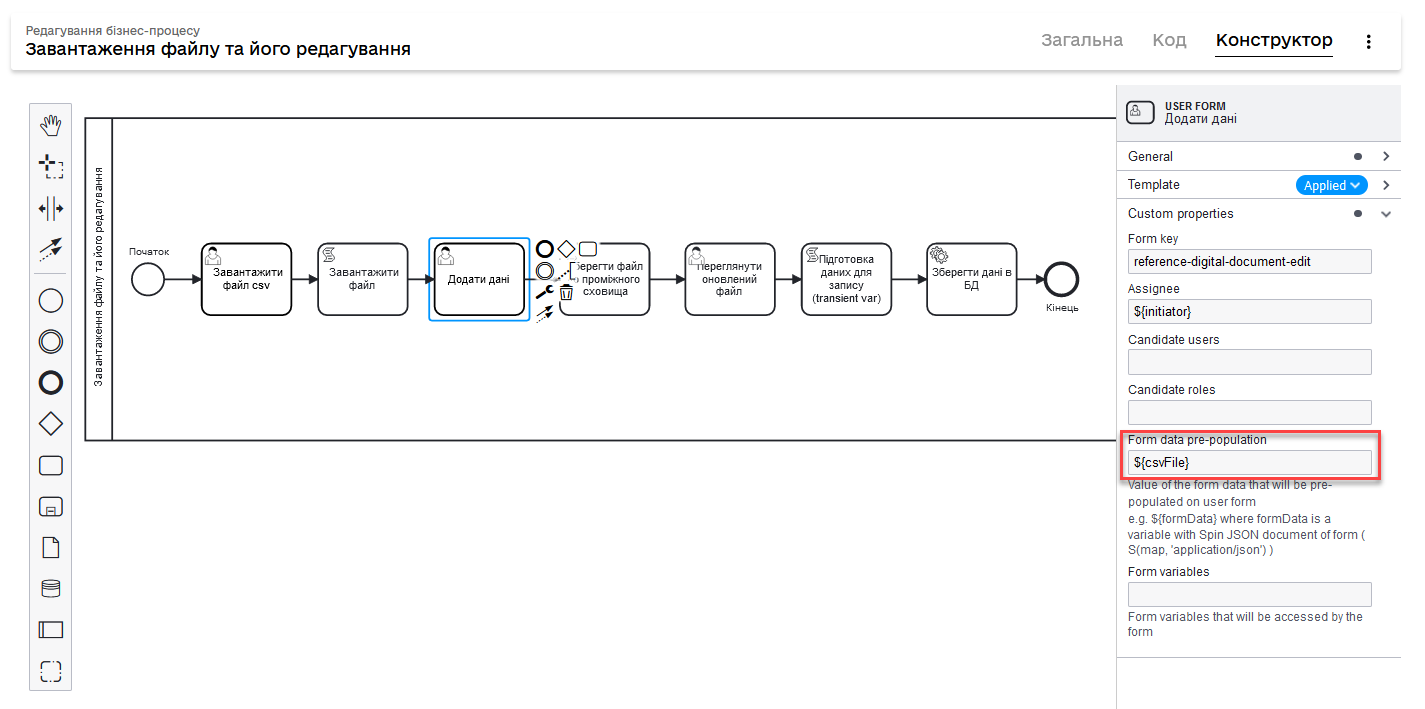
-
Змоделюйте скрипт-задачу (Script Task) та сформуйте скрипт для збереження цифрового документа до проміжного сховища. Для цього у скрипті використана JUEL-функція save_digital_document().
- Розглянемо більш детально Groovy-скрипт. Ви можете переглянути його у редакторі скриптів на скрипт-задачі:
-
Скрипт збереження завантаженого файлу до проміжного сховища даних
import groovy.json.JsonSlurper def payload = submission('UserTask_EditDocumentData').formData.prop('csvFile').elements() def records = new JsonSlurper().parseText(payload.toString()) def csvData = "\uFEFF" + originalHeaders.join(';') records.each { record -> def values = originalHeaders.collect { header -> record.get(header) } def csvRow = values.join(';') csvData += '\n' + csvRow } def content = csvData.getBytes('UTF-8') def fileName = originalMetadata.prop('name').value() def metadata = save_digital_document(content, fileName) def result = [:] result['uploadedFile'] = [metadata] set_variable('result', S(result, 'application/json'))Цей Groovy скрипт виконує декілька кроків, зокрема:
-
Отримує дані з форми під назвою
UserTask_EditDocumentData, які являють собою JSON об’єкт, та конвертує їх в об’єкт Groovy за допомогоюJsonSlurper.def payload = submission('UserTask_EditDocumentData').formData.prop('csvFile').elements() def records = new JsonSlurper().parseText(payload.toString()) -
Ініціює змінну
csvDataзі значеннями заголовків з оригінального файлу, що розділені символом;.def csvData = "\uFEFF" + originalHeaders.join(';') -
Перебирає записи JSON (що були CSV) та для кожного запису формує рядок CSV, додаючи його до
csvData.records.each { record -> def values = originalHeaders.collect { header -> record.get(header) } def csvRow = values.join(';') csvData += '\n' + csvRow } -
Конвертує
csvDataв байтовий масив із кодуваннямUTF-8.def content = csvData.getBytes('UTF-8') -
Зберігає оновлений документ в сервісі цифрових документів та отримує метадані документа.
def fileName = originalMetadata.prop('name').value() def metadata = save_digital_document(content, fileName) -
Створює об’єкт, який містить метадані завантаженого документа, та зберігає його у змінній
resultпроцесу.def result = [:] result['uploadedFile'] = [metadata] set_variable('result', S(result, 'application/json'))В сукупності, цей скрипт виконує задачу конвертації JSON формату назад у CSV, зберігає оновлений CSV документ в сервісі цифрових документів, та зберігає метадані нового документа в змінній процесу.
-
-
Аналогічно до кроку 3, передайте дані з оновленого файлу на UI-форму, лише на цей раз у полі Form data pre-population вкажіть змінну
${result}, отриману у попередньому скрипті. Ця форма покаже вам інформацію про файл. -
Змоделюйте скрипт-задачу та використайте скрипт, щоб підготувати дані, отримані з цифрового документа, для збереження до сховища даних реєстру.
set_transient_variable('payload', submission('UserTask_ViewEditedFileAndSign').formData.prop('uploadedFile').elements().first())Скрипт отримує дані із задачі
UserTask_ViewEditedFileAndSignчерез функціїsubmission(), обробляє їх та зберігає до тимчасової змінноїpayloadза допомогою функціїset_transient_variable(). -
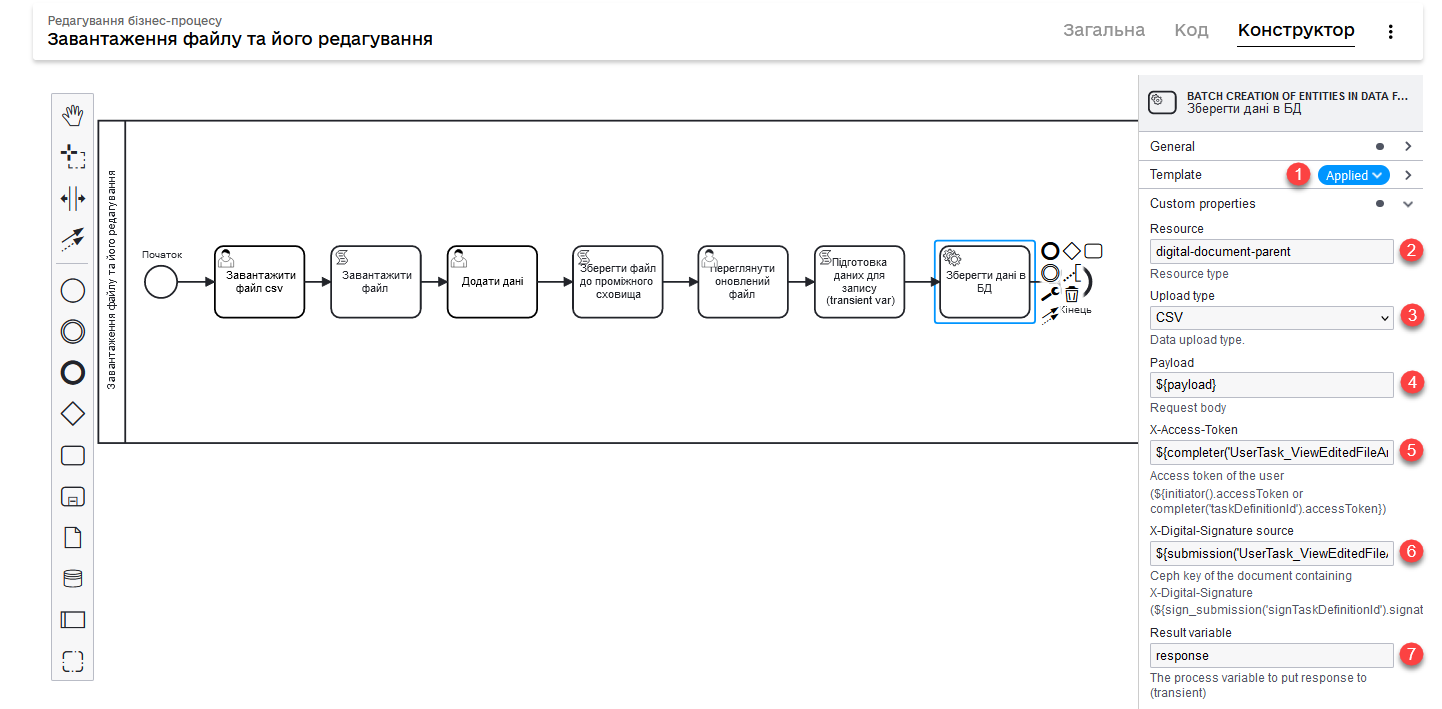
Збережіть дані до постійного сховища. Для цього створіть сервісну задачу (Service Task) та використайте делегат Batch creation of entities in data factory.
Використання делегата при завантаженні файлів детально описано тут: Створення сутностей масивом у фабриці даних (Batch creation of entities in data factory v2).