Завдання 1. Моделювання структур бази даних реєстру
- 1. Мета завдання
- 2. Завдання
- 3. План розробки фізичної моделі даних
- 4. Створення таблиць і зв’язків між ними
- 5. Створення критеріїв пошуку для інтеграції з формами бізнес-процесів
- 5.1. Пошук області в таблиці «КОАТУУ»
- 5.2. Пошук населеного пункту за назвою та кодом області в таблиці «КОАТУУ»
- 5.3. Пошук типу власності за назвою в таблиці «Тип Власності»
- 5.4. Пошук лабораторій за назвою або кодом ЄДРПОУ в таблиці «Лабораторія»
- 5.5. Пошук співробітника за іменем у таблиці «Кадровий Склад»
- 6. Первинне завантаження даних
- 7. Застосування розробленої моделі до бази даних
1. Мета завдання
- Виконання цього завдання має на меті:
-
-
Навчити моделювати структури бази даних.
-
Навчити розробляти XML-шаблони Liquibase для розгортання структур у базі даних реєстру.
-
Навчити створювати критерії пошуку у БД (Search Conditions) для інтеграції фабрики даних із бізнес-процесами.
-
2. Завдання
Створити структуру бази даних для збереження й обробки інформації із сертифікації лабораторій відповідно до наступної логічної моделі даних:
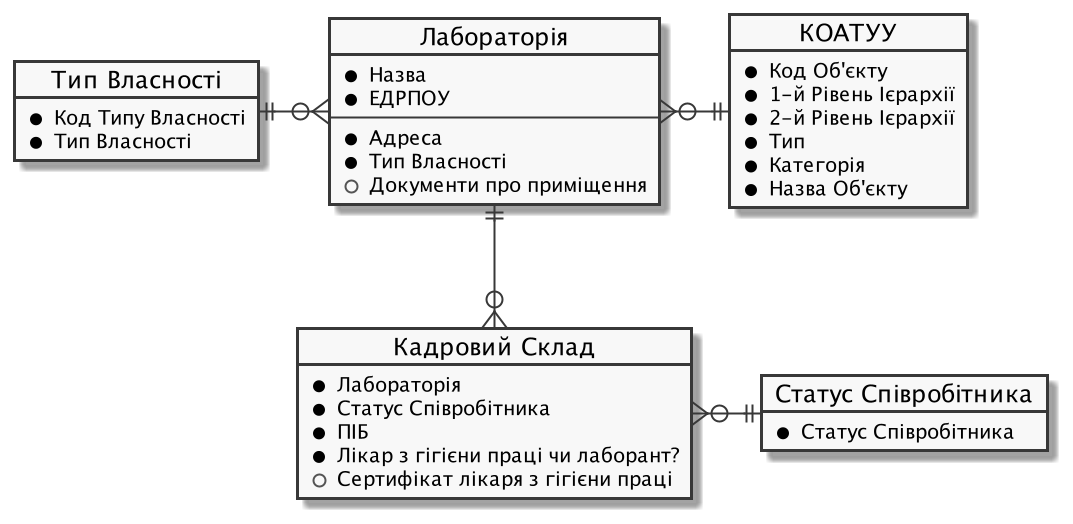
3. План розробки фізичної моделі даних
-
Визначити первинні ключі для кожної із сутностей.
-
Визначити вторинні ключі, якщо вони є в сутності.
-
Визначити обов’язкові поля.
-
Визначити поля або комбінацію полів, що мають унікальні значення.
-
Визначити назву таблиць та полів латиницею.
4. Створення таблиць і зв’язків між ними
-
Використовуючи інформацію, визначену у плані розробки фізичної моделі даних, та відповідний XML-шаблон, поданий нижче, створіть порожній файл createTables.xml
Використовуйте готовий файл createTables.xml як приклад. -
Скопіюйте метадані із шаблону XML-файлу, поданого нижче, та додайте до свого файлу як є, без змін.
Приклад. Шаблон XML-файлу<?xml version="1.0" encoding="UTF-8"?> <databaseChangeLog xmlns="http://www.liquibase.org/xml/ns/dbchangelog" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:ext="http://www.liquibase.org/xml/ns/dbchangelog-ext" xsi:schemaLocation="http://www.liquibase.org/xml/ns/dbchangelog http://www.liquibase.org/xml/ns/dbchangelog/dbchangelog-4.2.xsd http://www.liquibase.org/xml/ns/dbchangelog-ext https://nexus.apps.envone.dev.registry.eua.gov.ua/nexus/repository/extensions/com/epam/digital/data/platform/liquibase-ext-schema/latest/liquibase-ext-schema-latest.xsd"> </databaseChangeLog>https://<link to central Nexus>/nexus/repository/extensions/com/epam/digital/data/platform/liquibase-ext-schema/latest/liquibase-ext-schema-latest.xsd
-
Змінна
<link to central Nexus>- шлях до Nexus-сервера центральних компонентів (потрібно змінювати, наприклад, при перенесенні реєстру на інший кластер).
Кожен файл із розширенням .xml має містити системну інформацію зверху, всередині тегу
<databaseChangeLog>.Альтернативно використовуйте шаблон main-liquibase.xml із Gerrit-репозиторію як приклад для копіювання метаданих.
Файл main-liquibase.xml виконує функції "індексу" та через директиву
<include>встановлює посилання до інших XML-шаблонів, необхідних для розгортання структур даних. -
4.1. Порядок створення таблиць
Змініть порядок наборів змін (changeSet) у файлі createTables.xml таким чином, щоб таблиці, що мають зовнішні посилання до інших таблиць, створювались після тих, до яких вони посилаються. Тобто таблиці з лабораторіями мають створюватись після таблиць «КОАТУУ» та «Тип Власності».
Розташуйте набори змін для розгортання таблиць у наступному порядку:
-
«КОАТУУ»;
-
«Тип Власності»;
-
«Лабораторія»;
-
«Статус Співробітника»;
-
«Кадровий Склад».
4.2. Створення таблиці «Лабораторія»
| На прикладі таблиці «Лабораторія» розглянемо процес створення changeSets в рамках розгортання фізичної моделі даних. |
На цьому етапі необхідно створити нову таблицю із назвою «Лабораторія». Етап передбачає виконання наступних кроків:
- 1.Створюємо changeSet
-
На цьому кроці необхідно створити changeSet — набір атомарних змін в Liquibase.
У файлі createTables.xml, всередині тегу
<databaseChangeLog>, після метаданих, додайте тег<changeSet>.Таблиця 1. Обов’язкові атрибути Атрибут Значення idНаприклад,
"table laboratory"authorваші ПІБ
В результаті отримуємо наступну структуру:
<databaseChangeLog> ... ... <changeSet id="table laboratory" author="registry owner"> </changeSet> <changeSet id="table ownership" author="registry owner"> </changeSet> ... </databaseChangeLog> - 2. Додаємо коментар
-
Бажано, але не обов’язково, всередині тегу
<changeSet>додати тег<comment>з коментарем, що буде пояснювати, які саме зміни впроваджує цей changeSet.В результаті розширюємо нашу структуру наступним чином:
<databaseChangeLog> ... ... <changeSet id="table laboratory" author="registry owner"> <comment>Створюємо таблицю laboratory</comment> </changeSet> </databaseChangeLog> - 3. Додаємо тег createTable
-
На цьому кроці необхідно створити порожню таблицю.
Всередині тегу
<changeSet>додайте тег<createTable>із назвою таблиці «Лабораторія» латиницею.Таблиця 2. Обов’язкові атрибути Атрибут Значення tableName"laboratory"ext:historyFlag"true"В результаті розширюємо нашу структуру наступним чином:
<databaseChangeLog> ... ... <changeSet id="table laboratory" author="registry owner"> <comment>Створюємо таблицю laboratory</comment> <createTable tableName="laboratory" ext:historyFlag="true"> </createTable> </changeSet> </databaseChangeLog>В рамках процесу верифікації регламенту, флаг
historyFlagзі значеннямtrueвимагається при використанні уchangeSetтегів<createTable>або<addColumn>. Тому при створенні таблиці необхідно вказувати відповідне значенняhistoryFlag="true".Таким чином, буде додатково згенерована історична таблиця, і для кожної з таблиць буде згенеровано свій специфічний набір службових полів.
Детальна інформація про атрибут
ext:historyFlagдоступна за посиланням: - 4. Додаємо тег column
-
На цьому кроці необхідно зазначити стовпці, що міститиме таблиця.
Для кожного поля, що було визначено для таблиці «Лабораторія» у плані розробки фізичної моделі даних, всередині тегу
<createTable>додайте тег<column>, зазначивши назву стовпця та тип даних, що зберігатимуться.Таблиця 3. Атрибути Атрибут Значення nameНазва стовпця
typeТип даних
Наприклад,
"INT".В результаті розширюємо нашу структуру наступним чином:
<databaseChangeLog> ... ... <changeSet id="table laboratory" author="registry owner"> <comment>Створюємо таблицю laboratory</comment> <createTable tableName="laboratory" ext:historyFlag="true"> <column name="<назва стовпця>" type="<тип даних>"> </column> </createTable> </changeSet> </databaseChangeLog>-
Для змінної
<назва стовпця>введіть назву стовпця латиницею. -
Для змінної
<тип даних>зазначте тип даних.
-
- 5. Додаємо тег constraints
-
На цьому кроці необхідно зазначити обмеження для кожного стовпця таблиці.
-
Для стовпця, визначеного як первинний ключ, додайте підлеглий тег
<constraints>із наступними атрибутами:Таблиця 4. Атрибути Атрибут Значення nullable"false"primaryKey"true"primaryKeyNameНаприклад,
"pk_laboratory_id".Тип даних стовпця:
UUIDНазва первинного ключа має бути унікальною.
defaultValueComputed"uuid_generate_v4()"Значення ключа за замовчуванням.
Атрибут
nullable="false"вимагається для всіх стовпців, що, відповідно до бізнес-логіки, не допускають нульових значень.Необхідно використовувати ЛИШЕ тип
UUIDдля усіх ключів таблиць і функціюuuid_generate_v4()як значення за замовчуванням. Ця функція згенерує випадкове числове значення (див. https://www.uuidgenerator.net/version4). -
Для усіх зовнішніх посилань додайте тег
<constraints>з атрибутамиforeignKeyName,referencedTableNameтаreferencedColumnNames, зазначивши в них унікальну назву зовнішнього ключа, таблиці та стовпця, до яких вони посилаються:Таблиця 5. Атрибути Атрибут Значення foreignKeyName"fk_<Унікальна назва зовнішнього ключа>"referencedTableName"<Назва таблиці, до якої посилається зовнішній ключ>"referencedColumnNames"<Назва стовпця таблиці, до якого посилається зовнішній ключ>"На початку значення атрибута foreignKeyNameдодайте відповідний префіксfk_, що вказуватиме на зв’язок із зовнішньою таблицею.При додаванні зовнішніх ключів, зверніть увагу на порядок створення таблиць.
-
- У результаті отримуємо наступну структуру:
-
Приклад. ChangeSet із тегом для створення таблиці
laboratory<databaseChangeLog> ... ... <changeSet id="table laboratory" author="registry owner"> <comment>Створюємо таблицю laboratory</comment> <createTable tableName="laboratory" ext:historyFlag="true"> <column name="laboratory_id" type="UUID"> <constraints nullable="false" primaryKey="true" primaryKeyName="pk_laboratory_id"/> </column> <column name="name" type="TEXT"> <constraints nullable="false"/> </column> <column name="ownership_id" type="UUID"> <constraints nullable="false" foreignKeyName="fk_laboratory_ownership" referencedTableName="ownership" referencedColumnNames="ownership_id"/> </column> </createTable> </changeSet> </databaseChangeLog>Для всіх полів, що мають містити лише унікальний набір значень, додайте тег
<constraints>з атрибутамиunique="true"таuniqueConstraintName(опціонально):Приклад. Створення таблиці з обмеженнямunique<changeSet id="table ownership" author="registry owner"> <createTable tableName="ownership" ext:historyFlag="true" remarks="Довідник форм власності"> <column name="ownership_id" type="UUID" defaultValueComputed="uuid_generate_v4()"> <constraints nullable="false" primaryKey="true" primaryKeyName="pk_ownership_id"/> </column> <column name="code" type="TEXT" remarks="Код"> <constraints nullable="false"/> </column> <column name="name" type="TEXT" remarks="Назва"> <constraints nullable="false" unique="true"/> </column> </createTable> </changeSet>У випадку, коли декілька полів мають складати унікальне значення, після тегу
<createTable>додайте тег<addUniqueConstraint>, зазначивши в атрибутіtableNameназву таблиці, на яку накладається обмеження, а в атрибутіcolumnNames— перелік полів, що у комбінації мають бути унікальними.Приклад. Створення таблиці з тегом<addUniqueConstraint><createTable> ... ... </createTable> <addUniqueConstraint tableName="laboratory" columnNames="name,edrpou"/>
|
Принцип створення подальших таблиць є аналогічним зазначеному в прикладі з таблицею «Лабораторія». Структура параметрів у таблицях, що створюються, однакова для всіх таблиць у цьому завданні. |
4.3. Створення таблиці «КОАТУУ»
За аналогією до пункту Створення таблиці «Лабораторія», створіть таблицю із назвою «КОАТУУ» (стовпці доступні в createTables.xml):
-
В кінець тегу
<databaseChangeLog>файлу createTables.xml додайте тег<changeSet>, що визначає набір змін. -
Всередині тегу
<changeSet>додайте тег<createTable>із назвою таблиці «КОАТУУ» латиницею (наприклад,"koatuu"). -
Додайте теги
<column>для кожного стовпця таблиці «КОАТУУ», визначеної у пункті План розробки фізичної моделі даних. -
У тегу
<constraints>визначте первинний ключ таблиці, а також всі обов’язкові поля.
4.4. Створення таблиці «Тип Власності»
За аналогією до пункту Створення таблиці «Лабораторія», створіть таблицю із назвою «Тип Власності»:
-
В кінець тегу
<databaseChangeLog>файлу createTables.xml додайте тег<changeSet>, що визначає набір змін. -
Всередині тегу
<changeSet>додайте тег<createTable>із назвою таблиці «Тип Власності» латиницею (наприклад,"ownership"). -
Додайте теги
<column>для кожного стовпця таблиці «Тип Власності», визначеної в пункті План розробки фізичної моделі даних. -
У тегу
<constraints>визначте первинний ключ таблиці, а також всі обов’язкові поля.
4.5. Створення таблиці «Статус Співробітника»
За аналогією до пункту Створення таблиці «Лабораторія», створіть таблицю із назвою «Статус Співробітника»:
-
В кінець тегу
<databaseChangeLog>файлу createTables.xml додайте тег<changeSet>, що визначає набір змін. -
Всередині тегу
<changeSet>додайте тег<createTable>із назвою таблиці «Статус Співробітника» латиницею (наприклад,"staff_status"). -
Додайте теги
<column>для кожного стовпця таблиці «Статус Співробітника», визначеної у пункті План розробки фізичної моделі даних. -
У тегу
<constraints>визначте первинний ключ таблиці, а також всі обов’язкові поля.
4.6. Створення таблиці «Кадровий склад»
За аналогією до пункту Створення таблиці «Лабораторія», створіть таблицю із назвою «Кадровий склад»:
-
В кінець тегу
<databaseChangeLog>файлу createTables.xml додайте тег<changeSet>, що визначає набір змін. -
Всередині тегу
<changeSet>додайте тег<createTable>із назвою таблиці «Кадровий Склад» латиницею (наприклад,"staff"). -
Додайте теги
<column>для кожного стовпця таблиці «Кадровий Склад», визначеної у пункті План розробки фізичної моделі даних. -
У тегу
<constraints>визначте первинний ключ таблиці, всі зовнішні посилання до інших таблиць, а також всі обов’язкові поля.
5. Створення критеріїв пошуку для інтеграції з формами бізнес-процесів
Критерії пошуку (Search Conditions) — спеціальні об’єкти, що використовуються формами та бізнес-процесами для отримання набору даних з однієї або декількох таблиць реєстру.
На рівні бази даних вони реалізовуються через представлення (views), визначені SQL-запитом до однієї або декількох таблиць.
Для створення критеріїв пошуку використовується тег <ext:createSearchCondition>, розроблений в рамках розширення інструмента створення та керування фізичною моделлю даних Liquibase на Платформі реєстрів.
<changeSet author="registry owner" id="SearchCondition">
<ext:createSearchCondition name="SearchCondition" limit="1">
<ext:table name="table_one" alias="to">
<ext:column name="name" alias="to_name"/>
<ext:column name="type" searchType="equal"/>
<ext:function name="count" alias="cnt" columnName="uuid"/>
</ext:table>
<ext:table name="table_two" alias="tt">
<ext:column name="name" alias="tt_name"/>
<ext:column name="code" searchType="contains"/>
<ext:function name="sum" alias="sm" columnName="code"/>
</ext:table>
<ext:join type="left">
<ext:left alias="to">
<ext:column name="name"/>
</ext:left>
<ext:right alias="tt">
<ext:column name="name"/>
</ext:right>
</ext:join>
<ext:where>
<ext:condition tableAlias="to" columnName="type" operator="eq" value="'char'">
<ext:condition logicOperator="or" tableAlias="to" columnName="type" operator="eq" value="'text'"/>
</ext:condition>
<ext:condition logicOperator="and" tableAlias="tt" columnName="code" operator="similar" value="'{80}'"/>
</ext:where>
</ext:createSearchCondition>
</changeSet>-
Створіть для критеріїв пошуку окремий файл createSearchConditions.xml з того ж шаблону, що і createTables.xml.
Використовуйте готовий файл createSearchConditions.xml як приклад. -
За аналогією до таблиць, створіть наступні критерії пошуку в окремих наборах змін (changeSet).
5.1. Пошук області в таблиці «КОАТУУ»
-
Використовується бізнес-процесом: Додавання лабораторії.
-
Назва критерію пошуку:
koatuu_obl_contains_name. -
Пошук за полем:
name, тип пошуку:contains. -
Сортування за полем:
name, напрямок:asc.
<changeSet author="registry owner" id="searchCondition koatuu_obl_contains_name">
<ext:createSearchCondition name="koatuu_obl_contains_name">
<ext:table name="koatuu" alias="k">
<ext:column name="koatuu_id"/>
<ext:column name="code"/>
<ext:column name="name" sorting="asc" searchType="contains"/>
</ext:table>
<ext:where>
<ext:condition tableAlias="k" columnName="type" operator="eq" value="'О'"/>
</ext:where>
</ext:createSearchCondition>
</changeSet>SELECT k.koatuu_id,
k.code,
k.name
FROM koatuu k
WHERE k.type = 'О'::text
ORDER BY k.name;5.2. Пошук населеного пункту за назвою та кодом області в таблиці «КОАТУУ»
-
Використовується бізнес-процесом: Додавання лабораторії.
-
Назва критерію пошуку:
koatuu-np-starts-with-name-by-obl. -
Пошук за полем:
name, тип пошуку:startWith. -
Пошук за полем:
level1, тип пошуку:equal. -
Сортування за полем:
name, напрямок:asc.
<changeSet author="registry owner" id="searchCondition koatuu_np_starts_with_name_by_obl">
<ext:createSearchCondition name="koatuu_np_starts_with_name_by_obl" limit="100">
<ext:table name="koatuu" alias="np">
<ext:column name="koatuu_id"/>
<ext:column name="name" searchType="startsWith" sorting="asc"/>
<ext:column name="level1" searchType="equal"/>
</ext:table>
<ext:table name="koatuu" alias="rn">
<ext:column name="name" alias="name_rn"/>
</ext:table>
<ext:join type="left">
<ext:left alias="np">
<ext:column name="level2"/>
</ext:left>
<ext:right alias="rn">
<ext:column name="code"/>
</ext:right>
<ext:condition logicOperator="and" tableAlias="rn" columnName="type" operator="eq" value="'Р'"/>
</ext:join>
<ext:where>
<ext:condition tableAlias="np" columnName="type" operator="eq" value="'НП'"/>
</ext:where>
</ext:createSearchCondition>
</changeSet>SELECT np.koatuu_id,
np.name,
np.level1,
rn.name AS name_rn
FROM koatuu np
LEFT JOIN koatuu rn ON np.level2 = rn.code AND rn.type = 'Р'::text
WHERE np.type = 'НП'::text
ORDER BY np.name;5.3. Пошук типу власності за назвою в таблиці «Тип Власності»
-
Використовується бізнес-процесом: Додавання лабораторії.
-
Назва критерію пошуку:
ownership-contains-name. -
Пошук за полем:
name, тип пошуку:contains. -
Сортування за полем:
name, напрямок:asc.
<changeSet author="registry owner" id="searchCondition ownership_contains_name">
<ext:createSearchCondition name="ownership_contains_name">
<ext:table name="ownership" alias="o">
<ext:column name="ownership_id"/>
<ext:column name="code"/>
<ext:column name="name" sorting="asc" searchType="contains"/>
</ext:table>
</ext:createSearchCondition>
</changeSet>SELECT o.ownership_id,
o.code,
o.name
FROM ownership o
ORDER BY o.name;5.4. Пошук лабораторій за назвою або кодом ЄДРПОУ в таблиці «Лабораторія»
5.4.1. Приклад створення критерію пошуку №1
-
Використовується бізнес-процесом: Додавання лабораторії.
-
Назва критерію пошуку:
laboratory-equal-edrpou-name-count. -
Пошук за полем:
edrpou, тип пошуку:equal. -
Пошук за полем:
name, тип пошуку:equal.
<changeSet author="registry owner" id="searchCondition laboratory_equal_edrpou_name_count">
<comment>CREATE search condition laboratory_equal_edrpou_name_count</comment>
<ext:createSearchCondition name="laboratory_equal_edrpou_name_count">
<ext:table name="laboratory">
<ext:function name="count" alias="cnt" columnName="laboratory_id"/>
<ext:column name="edrpou" searchType="equal"/>
<ext:column name="name" searchType="equal"/>
</ext:table>
</ext:createSearchCondition>
</changeSet>SELECT laboratory.edrpou,
laboratory.name,
count(laboratory.laboratory_id) AS cnt
FROM laboratory
GROUP BY laboratory.edrpou,
laboratory.name;5.4.2. Приклад створення критерію пошуку №2
-
Використовується бізнес-процесом: Внесення даних в кадровий склад.
-
Назва критерію пошуку:
laboratory-start-with-edrpou-contains-name. -
Пошук за полем:
edrpou, тип пошуку:startsWith. -
Пошук за полем:
name, тип пошуку:contains.
<changeSet author="registry owner" id="searchCondition laboratory_start_with_edrpou_contains_name">
<comment>CREATE search condition laboratory_start_with_edrpou_contains_name</comment>
<ext:createSearchCondition name="laboratory_start_with_edrpou_contains_name">
<ext:table name="laboratory">
<ext:column name="laboratory_id"/>
<ext:column name="edrpou" searchType="startsWith"/>
<ext:column name="name" searchType="contains"/>
</ext:table>
</ext:createSearchCondition>
</changeSet>SELECT laboratory.laboratory_id,
laboratory.edrpou,
laboratory.name
FROM laboratorySELECT laboratory.laboratory_id,
laboratory.edrpou,
laboratory.name
FROM laboratory
WHERE laboratory.name LIKE '%name%' AND laboratory.edrpou LIKE 'edrpou%'
Input parameters: name, edrpou5.5. Пошук співробітника за іменем у таблиці «Кадровий Склад»
-
Використовується бізнес-процесом: Додавання персоналу.
-
Назва критерію пошуку:
staff-contains-name. -
Пошук за полем:
name, тип пошуку:contains. -
Сортування за полем:
name, напрямок:asc.
<changeSet author="registry owner" id="searchCondition staff_contains_name">
<comment>CREATE search condition staff_contains_name</comment>
<ext:createSearchCondition name="staff_contains_name">
<ext:table name="staff_status" alias="s">
<ext:column name="staff_status_id"/>
<ext:column name="name" sorting="asc" searchType="contains"/>
</ext:table>
</ext:createSearchCondition>
</changeSet>SELECT s.staff_status_id,
s.name
FROM staff_status s
ORDER BY s.name;6. Первинне завантаження даних
Для правильного наповнення та оперування даними реєстру, таблиці-довідники повинні містити дані. Їх завантаження можливе до початку роботи самого реєстру через виклик спеціальної функції бази даних. Виклик функції можливий через відповідний Liquibase-тег – <sql>.
Приклад XML-шаблону із набором змін для початкового завантаження даних
<property name="dataLoadPath" value="/tmp/data-load/"/>
<changeSet author="registry owner" id="load data to dictionaries">
<sql dbms="postgresql" endDelimiter=";" splitStatements="true" stripComments="true">
CALL p_load_table_from_csv('staff_status','${dataLoadPath}dict_status_spivrobitnyka.csv', array['code','name','constant_code'], array['name','constant_code']);
CALL p_load_table_from_csv('ownership','${dataLoadPath}dict_formy_vlasnosti.csv', array['code','name']);
<!--
Наступний приклад використання функції актуальний лише в рамках Реєстру атестованих лабораторій для первинного завантаження довідника КОАТУУ.
Не передбачається подальше використання довідника КОАТУУ при розгортанні моделі даних.
Приклад:
CALL p_load_table_from_csv(
'koatuu'
,'${dataLoadPath}dict_koatuu.csv'
, array['code','category','name']
, array['code','category','name'
,'level1::substring(code,1,2)||''00000000'''
,'level2::substring(code,1,5)||''00000'''
,'type::CASE WHEN code ~ ''[0-9]{2}0{8}'' AND code !~ ''(80|85)0{8}'' THEN ''О''
WHEN code ~ ''[0-9]{2}2[0-9]{2}0{5}'' AND code !~ ''[0-9]{2}20{7}'' THEN ''Р''
WHEN coalesce(category, ''Р'') != ''Р''
OR code IN (SELECT DISTINCT substring(code,1,5)||''00000'' FROM koatuu_csv k2 WHERE category = ''Р'') AND category IS NULL
OR code ~ ''(80|85)0{8}'' THEN ''НП''
ELSE NULL END']
);
-->
</sql>
</changeSet>
Для первинного завантаження довідника КОАТУУ функція CALL p_load_table_from_csv() використовується ЛИШЕ в рамках Реєстру атестованих лабораторій. Не передбачається подальше використання довідника КОАТУУ при розгортанні моделі даних.
|
- Виконайте наступні кроки, щоб здійснити первинне завантаження:
-
-
Створіть файл populateDictionaries.xml із того ж шаблону, що і createTables.xml.
Використовуйте готовий файл populateDictionaries.xml як приклад. -
Додайте окремий тег
<changeSet>із набором змін. -
Всередині тегу
<changeSet>додайте тег<sql>з атрибутомdbms="postgresql". -
Всередині тегу
<sql>додайте виклики функціїp_load_table_from_csv()для кожної таблиці довідника.Приклад 1. Вхідні параметри функціїCALL p_load_table_from_csv('research','${dataLoadPath}dict_typy_doslidzhen.csv', array['code','research_type'], array['research_type']);де:
-
'staff_status'='p_table_name'— назва таблиці в базі даних, до якої завантажуватимуться дані; -
${dataLoadPath}dict_typy_doslidzhen.csv='p_file_name'— повний шлях до файлу з даними. -
array['code','name','constant_code']=p_table_columns— масив з переліком полів csv-файлу; -
array['name','constant_code']=p_target_table_columns— масив з переліком полів для завантаження до цільової таблиці.
Назви полів, що зазначені у параметрі
p_table_columns, можуть не відповідати назвам у файлі — вони можуть бути використані у наступному параметріp_target_table_columnsдля трансформації даних.Назви полів з параметра
p_target_table_columnsмають відповідати переліку з параметраp_table_columns(якщо поля таблиці повністю відповідають полям у файлі, цей параметр можна не вказувати). -
-
|
Після внесення змін до моделі даних в Gerrit-репозиторії, всі файли з папки data-model/data-load копіюються до папки /tmp/data-load на сервері бази даних. Тому шлях до файлу повинен виглядати наступним чином: /tmp/data-load/<назва файлу>.csv, де:
|
У результаті отримуємо 3 виклики функцій, що завантажують дані до таблиць-довідників із наступних файлів:
| Довідник | Файл з даними |
|---|---|
КОАТУУ (опціонально) |
|
Тип Власності |
|
Статус Співробітника |
7. Застосування розробленої моделі до бази даних
Платформа використовує файл main-liquibase.xml як основний для розгортання моделі даних реєстру.
| Всі набори змін, що будуть включені до файлу main-liquibase.xml, застосуються в базі даних. |
Для включення набору змін із файлів, створених протягом минулих кроків, використовується тег <include> з атрибутом file, що вказує шлях до XML-файлу. Поточною директорією для Liquibase є коренева папка Gerrit-репозиторію — тому шлях до файлів має наступний вигляд: data-model/*.xml.
- Щоб застосувати розроблену модель, виконайте наступні кроки:
-
-
Створіть файл main-liquibase.xml із того ж шаблону, що і createTables.xml.
Використовуйте готовий шаблон main-liquibase.xml із Gerrit-репозиторію як приклад. -
Додайте тег
<include>для кожного з файлів, створених протягом минулих етапів, зазначивши шлях до файлу в атрибутіfile.Приклад вставки файлу в XML-шаблоні<include file="data-model/createTables.xml"/>Обов’язково додайте контекст для первинного завантаження даних.
Щоб правильно розгорнути модель даних вашого реєстру, необхідно обов’язково вказати атрибут
context="pub"в рамках тегу<include>. Наприклад, ви хочете включити до розгортання моделі файл, що містить процедури наповнення таблиць-довідників первинними даними, — populateDictionaries.xml.Приклад 2. Додавання контексту context="pub" для наповнення таблиць даними<include file="data-model/populateDictionaries.xml" context="pub"/>Схема містить елемент <include>, який посилається на зовнішній файл "populateDictionaries.xml". При цьому контекст "pub" вказує на те, що елементи, які містяться в цьому файлі, будуть використані в операційній базі даних реєстру.
-
Покладіть файли XML до папки data-model Gerrit-репозиторію.
-
Файли з даними скопіюйте до папки data-model/data-load.
Усього маємо отримати 7 файлів для розгортання моделі даних та первинного наповнення БД:
- 4 файли із шаблонами XML:
- 3 файли CSV із довідниками для первинного наповнення:
-
Змініть версію регламенту у файлі settings.yaml, що розміщується у кореневій папці Gerrit-репозитарію.
Версію регламенту необхідно змінювати кожного разу коли вносяться зміни у data-model.
При зміні бізнес-процесів, конфігурацій, форм чи звітів змінювати версію в
settings.yamlне потрібно. -
Застосуйте зміни до Gerrit (
commit,push). -
Пройдіть процедуру рецензування коду вашого коміту (Code Review). У разі відсутності відповідних прав, зверніться до відповідальної особи.
-
Дочекайтеся виконання Jenkins-pipeline MASTER-Build-registry-regulations.
-
|
Корисна документація по роботі з Liquibase: |