Виведення Платформи та реєстрів у промислову експлуатацію
- 1. Підготовчі дії на рівні Платформи
- 1.1. Базові передумови
- 1.2. Навчання технічного адміністратора реєстру
- 1.3. Планування резервного сховища бекапів Платформи та реєстрів
- 1.4. Планування місця для сховищ центральних компонентів Платформи
- 1.5. Планування місця для кореневих томів файлової системи Ceph
- 1.6. Зберігання цифрових печаток адміністратора для платформи та реєстрів
- 1.7. Налаштування взаємодії з "Трембітою" та встановлення Шлюзу Безпечного Обміну (ШБО)
- 1.8. Первісна перевірка після розгортання Платформи
- 1.9. Налаштування відправлення повідомлень моніторингу
- 1.10. Налаштування базових бордів в Kibana
- 1.11. Налаштування бекапів центральних компонент
- 1.12. Налаштування ключів цифрового підпису Платформи
- 1.13. Налаштування та отримання дозволу для поштового сервера в AWS-середовищі
- 1.14. Налаштування обмежень доступу на мережевому рівні до адміністративних ендпоінтів Платформи
- 1.15. Захист інфраструктури цільових оточень
- 1.16. Оновлення компонентів
- 1.17. Міграція реєстрів
- 2. Підготовчі дії на рівні реєстрів
- 2.1. Рекомендації щодо формування команд підтримки реєстрів L1, L2, L3
- 2.2. Створення реєстру та його первинна перевірка
- 2.3. Оновлення компонентів реєстру
- 2.4. Спеціальні кроки для оновлення реєстру
- 2.5. Типові проблеми з автентифікацією користувачів реєстру та при підписанні бізнес-процесів
- 2.6. Зміна режиму розгортання реєстру з production на development
- 2.7. Особливості розгортання регламенту в production-середовищі
- 2.8. Рекомендований алгоритм внесення змін до регламенту реєстру
- 2.9. Налаштування ключів та сертифікатів цифрового підпису реєстру
- 2.10. Налаштування поштового сервера (SMTP-сервер)
- 2.11. Налаштування взаємодії з Дією
- 2.12. Налаштування взаємодії з іншими реєстрами та зовнішніми системами
- 2.13. Налаштування взаємодії через Трембіту на базі стандартних конекторів
- 2.14. Конфігурація реєстру під навантаження
- 2.15. Планування місця для сховищ реєстру
- 2.16. Отримання доступу для L2 до системи сповіщень, моніторингу та логування у реєстрі
- 2.17. Налаштування бекапів
- 2.18. Інтеграція з id.gov.ua та використання стилізованого віджета
- 2.19. Визначення порядку надання доступу посадовим особам
- 2.20. Рекомендації щодо онбордингу надавачів та отримувачів послуг
- 2.21. Аутентифікація юридичних осіб до реєстру як отримувачів послуг
- 2.22. Рекомендації щодо уникнення "покинутих" бізнес-процесів користувачами
- 2.23. Налаштування рейт-лімітів
- 2.24. Налаштування обмежень доступу на мережевому рівні до компонентів реєстру (CIDR)
- 2.25. Обмеження доступу на рівні IP до SOAP-роутів ШБО "Трембіта"
- 2.26. Налаштування власних DNS-імен
- 2.27. Додавання нових користувачів (через Keycloak та імпорт)
- 2.28. Призначення адміністраторів Платформи та реєстру
- 2.29. Розгортання геосервера та робота з геоданими у реєстрі
- 2.30. Первинне завантаження та дозавантаження даних до системи
- 3. Рекомендації щодо нефункціонального тестування реєстрів на платформі
- 4. Контрольний список для запуску публічного сервісу
- 5. Засвоєні уроки
1. Підготовчі дії на рівні Платформи
1.1. Базові передумови
Для виведення платформи реєстрів в промислову експлуатацію обов’язково слід використовувати віртуальні інфраструктури, що отримують офіційну підтримку (наразі це AWS та VSphere).
На таких інфраструктурах має бути встановлений OKD-кластер, версія якого відповідає вимогам Платформи, згідно з рекомендаціями, викладеними в офіційній документації Платформи (Вимоги до OKD-кластерів щодо інсталювання Платформи).
Встановлення та налаштування Платформи має виконуватися відповідно до вказівок, наданих в офіційній документації, і проводитися на середовищах, які підтримуються офіційно:
1.2. Навчання технічного адміністратора реєстру
Онбординг для адміністраторів реєстру має важливе значення з різних поглядів, зокрема:
-
Робота адміністратора реєстру потребує глибоких технічних знань. Це включає знання про структуру та функціонування реєстру, розуміння роботи його компонентів, а також здатність моніторингу та підтримки реєстру. Навчання допомагає адміністраторам отримати ці знання та навички, необхідні для ефективного виконання їх обов’язків.
-
Адміністратори реєстру відповідають за розробку та впровадження регламенту реєстру. Це включає розуміння логіки функціонування реєстру, моделі даних, бізнес-процесів та інтерфейсів користувача. Онбординг дозволяє адміністраторам зрозуміти ці особливості, що сприяє ефективній роботі.
-
Висвітлення всіх аспектів роботи в ролі адміністратора реєстру під час онбордингу може значно підвищити продуктивність роботи. Якщо адміністратори з самого початку розуміють свої обов’язки, цілі та очікування, вони зможуть швидше адаптуватися та ефективно виконувати свою роботу в межах великої розподіленої системи.
|
Більш детально ви можете ознайомитися із навчальними матеріалами адміністраторів реєстру на сторінках: |
1.3. Планування резервного сховища бекапів Платформи та реєстрів
Резервні копії Платформи та реєстрів зберігаються в окремому сховищі, сумісному з S3 — https://min.io/. Важливо врахувати їх розмір при плануванні доступного простору та обчислювальних ресурсів сховища.
|
Точне визначення обсягу потрібного місця для зберігання резервних копій є складним завданням, оскільки це залежить від особливостей кожного окремого реєстру. Нижче наведені приблизні дані для орієнтування. |
Резервне копіювання основних компонент вимагає поділу інсталяції на два типи — AWS та VSphere:
-
AWS: резервна копія ресурсів Openshift для основних компонент займає від 1 до 5 Мб. Для даних, що зберігаються у
PersistentVolumeClaim, створюється EBS Snapshot (https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/EBSSnapshots.html), а тому простір на Minio не використовується. Єдине виключення — одинPersistentVolumeClaimу просторі іменuser-management, для якого об’єм Minio складає 5 Мб. -
vSphere: розмір резервних копій ресурсів Openshift аналогічний AWS. Проте для зберігання резервних копій із
PersistentVolumeClaimsвикористовується Minio, який займає приблизно стільки місця для наступних компонентів:-
control-plane— 15 Гб; -
user-management— 12 Гб; -
control-plane-nexus— 100 Гб; -
grafana-monitoring— 10 Гб.
-
Цей розмір — розмір власне PVC, і можна вважати що на minio кожен проєкт буде займати стільки місця. Для центральних компонент слід розраховувати приблизно 140 Гб для резервних копій даних PVC, а ще 10 Гб — для ресурсів OpenShift (10 Гб закладено на перспективу).
Резервне копіювання реєстрів для AWS та VSphere не відрізняється, і для створення однієї резервної копії потрібно приблизно 210 Гб: 10 Гб для одного бекапу ресурсів Openshift та 200 Гб для бекапу PVC.
Щодо реплікації, початково рекомендується резервувати до 200 Гб. Проте, з розширенням реєстру, потреба у просторі може зрости до декількох терабайтів.
1.4. Планування місця для сховищ центральних компонентів Платформи
- Expand PVC
-
Центральні компоненти Платформи зберігаються у томах cloud-native-сховища. Розширити місце на дисках для таких компонентів можна через OpenShift-консоль, у розділі Storage > PersistentVolumeClaims >
Expand PVC, у відповідних проєктах (namespaces), зокрема:-
openshift-logging -
grafana-monitoring -
control-plane -
control-plane-nexus -
user-management(база даних Keycloak)
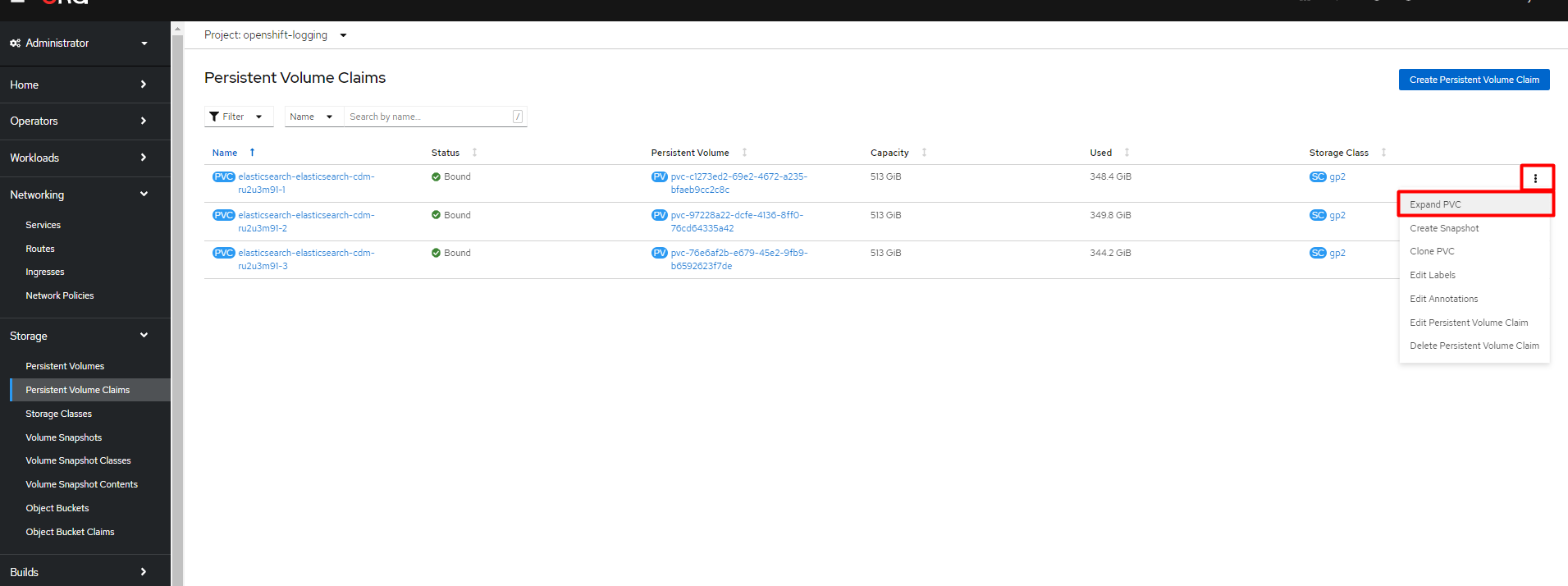 Зображення 1. Приклад розширення місця на дисках openshift-logging
Зображення 1. Приклад розширення місця на дисках openshift-logging -
- Custom resource definitions
-
Окрім цього потрібно визначити Custom resource definitions для певного компонента. Наприклад, для
openshift-loggingце виглядатиме так:-
Відкрийте Administration > Custom resource definitions та знайдіть ClusterLogging.
-
Натисніть Instance проєкту openshift-logging.
-
Відкрийте YAML-налаштування, знайдіть параметр
storage.sizeта змініть розмір диска.
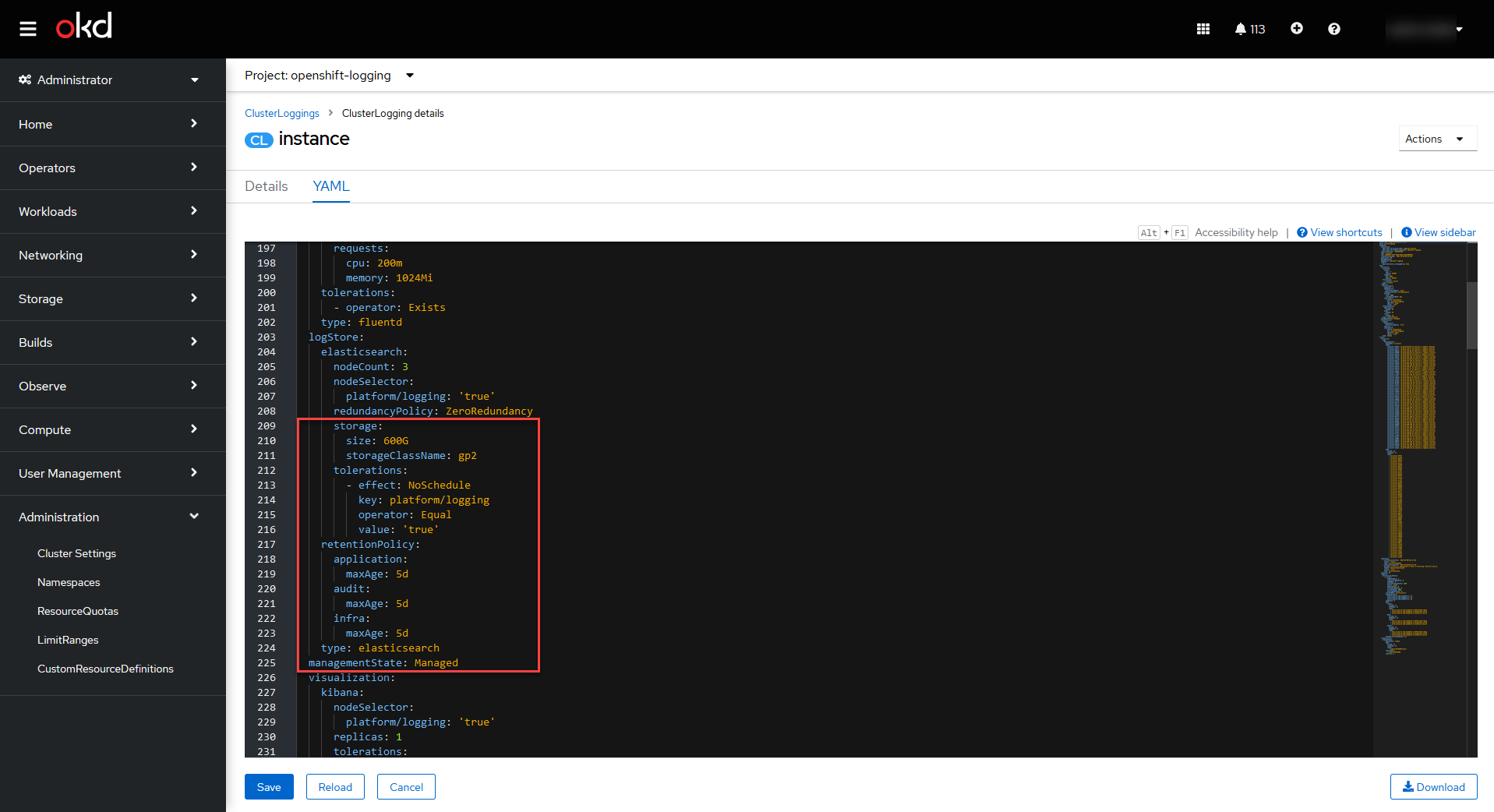 Зображення 2. Custom resource definitions для екземпляра openshift-logging
Зображення 2. Custom resource definitions для екземпляра openshift-logging -
Кожний сервіс запускається із налаштуваннями розміру дисків за замовчуванням. Ви як адміністратор можете залишити ці налаштування, або якщо ви чітко знаєте, що виділеного розміру дисків недостатньо для ваших потреб, тоді томи можна розширити одразу. Рекомендоване значення для збільшення місця на диску +50%. Наприклад, якщо розмір диска для openshift-logging за замовчування становить 400G, тоді для початку ви можете збільшити місце до 600G.
|
|
Більш детально з процесом розширення місця на дисках ви можете ознайомитися на прикладі технічного обслуговування EFK-стеку. Читайте сторінку Розширення місця в Elastic Search. |
1.5. Планування місця для кореневих томів файлової системи Ceph
Сервіс Ceph — це також центральний компонент Платформи, який має свою специфіку. Кореневі томи (root volumes) для Ceph зберігаються у проєкті openshift-storage.
Налаштувати розмір дисків для Ceph можна в OpenShift-консолі > проєкт openshift-storage > Storage > PersistentVolumeClaims.
| Рекомендоване значення для збільшення місця на диску +50%, як і для інших центральних компонентів. Наприклад, якщо розмір диска для Ceph за замовчування — 512G, тоді для початку ви можете збільшити місце до 750G. |
|
Детальніше про налаштування файлової системи ви можете дізнатися на сторінках: |
1.6. Зберігання цифрових печаток адміністратора для платформи та реєстрів
1.6.1. Мережний криптомодуль "Гряда"
У промисловій експлуатації рекомендованим сховищем зберігання ключів є програмно-апаратний комплекс "Гряда". Технічний адміністратор Платформи повинен мати змогу генерувати та сертифікувати ключі для Платформи та реєстрів, що будуть на ній розгорнуті.
"Гряда" встановлюється на окремому екземплярі, в тому ж ЦОД, але окремо від Платформи реєстрів. Налаштування криптомодуля як стороннього продукту виконує адміністратор "Гряди". На стороні Платформи адміністрування виконує технічний адміністратор Платформи. Для Платформи передбачений єдиний екземпляр "Гряди" для всіх реєстрів.
- Необхідно забезпечити мережеве з’єднання між Платформою реєстрів та "Грядою". Для цього:
-
-
На стороні криптомодуля "Гряда" необхідно дозволити трафік з OpenShift. За це відповідає адміністратор "Гряди". Адміністратор Платформи має надати IP-адреси, з яких необхідно дозволити трафік від Платформи реєстрів до "Гряди".
-
На поді DSO (сервіс цифрових підписів) реєстру необхідно дозволити вихідний трафік на "Гряду":
-
Відкрийте налаштування поди DSO-сервісу та перевірте конфігурацію
sidecar.istio:-
Якщо в анотації до сервісу вказано
sidecar.istio.io/inject: 'false', то трафік дозволено за замовчуванням, і додаткові налаштування не потрібні.metadata: annotations: sidecar.istio.io/inject: 'false' -
Якщо вказано
sidecar.istio.io/inject: 'true', зокрема:metadata: annotations: sidecar.istio.io/inject: 'true' traffic.sidecar.istio.io/excludeOutboundIPRanges: 10.129.71.251/32переконайтеся, що YAML-конфігурація на поді DSO має наступні анотації:
traffic.sidecar.istio.io/excludeOutboundIPRanges: {{ .Values.griada.ip }} traffic.sidecar.istio.io/excludeOutboundPorts: '{{ .Values.griada.port }}'-
де замість
{{ .Values.griada.ip }}буде IP-адреса "Гряди", наприклад,0.0.0.0; -
замість
'{{ .Values.griada.port }}'буде порт "Гряди", наприклад,3080.
-
-
-
Анотації з helm chart для DSO-сервісу автоматично сформуються, якщо у deploy-templates/values.yaml реєстру дозволено трафік на "Гряду" й вказані IP та порт.
griada: enabled: true ip: 0.0.0.0 port: 3080
-
-
Виконайте налаштування всередині самої Гряди, щоб технічний адміністратор Платформи мав змогу генерувати та сертифікувати ключі для Платформи та реєстрів, що будуть на ній розгорнуті.
-
Як встановити та налаштувати "Гряду, дивіться на офіційному сайті ІІТ: https://iit.com.ua/products.
-
Як налаштувати доступ до "Гряди" на локальній машині, дивіться на сторінці Налаштування локального доступу до криптомодуля "Гряда".
-
Як використовувати криптомодуль при роботі із ключами цифрового підпису на Платформі, див. на сторінках:
-
-
| Додатково ознайомтеся із розгортанням емулятора "Гряда" в AWS на сторінці Програмний емулятор криптомодуля Гряда-301 в AWS. |
1.6.2. Файлові ключі
Використання файлових ключів для підпису є методом, який не рекомендується і, відповідно до законодавства, не пройде Комплексної Системи Захисту Інформації (КСЗІ).
Забезпечення взаємодії реєстру з Акредитованим Центром Сертифікації Ключів (АЦСК) вимагає використання українських IP-адрес.
Якщо екземпляр реєстру не має українських IP, бо розміщений на хмарних ресурсах ЦОД AWS або іншого провайдера, тоді власник екземпляра повинен забезпечити додавання цих IP до білого списку відповідного АЦСК. Цей процес називається "whitelisting". Він дозволяє специфічним IP-адресам обходити певні обмеження мережі, таким чином надаючи змогу взаємодіяти з АЦСК.
| Важливо зауважити, що не всі хмарні сервіси дозволяють пряме управління IP-адресами. Тому власники екземплярів реєстрів мають розглянути можливості використання додаткових послуг або рішень для отримання українських IP-адрес або забезпечення їх "whitelisting". |
|
Детальніше про налаштування файлових ключів цифрового підпису ви можете дізнатися на сторінках: |
1.8. Первісна перевірка після розгортання Платформи
Після розгортання Платформи у цільовому середовищі, необхідно виконати первинне тестування Платформи, зокрема провести такі перевірки компонентів:
- Перевірки в OpenShift-консолі:
-
-
У компоненті
control-plane-jenkinsперевірте, що пайплайн MASTER-Build-cluster-mgmt завершився успішно, й усі кроки виконані. -
Перевірте, що поди
user-managementрозгорнулися, зокрема перевірте доступність сервісів Keycloak та DSO Платформи. -
Перевірте стан под
control-plane-nexus— вони мають бути у "хорошому" стані. -
Перевірте стан под компонента
openshift-logging. -
Виконайте вхід до сервісу моніторингу Grafana для перевірки його доступності.
-
Перевірте стан усіх под у проєктах
istio-systemтаistio-operator— вони повинні бути у станіOK. -
Перевірте компонент Jager: відкрийте сторінку Jager, автентифікуйтеся за допомогою системного користувача
KubeAdmin, виконайте вхід до сервісу Jager та перевірте, чи відкривається сторінка пошуку Jager.-
Перевірте компонент Kiali: відкрийте сторінку Kiali, автентифікуйтеся за допомогою системного користувача
KubeAdmin, виконайте вхід до сервісу Kiali та перевірте, чи відкривається домашня сторінка Kiali. -
Перевірте стан усіх под
openshift-logging— вони повинні бути у станіOK.
-
-
Перевірте стан усіх под в
openshift-storage, а також переконайтеся, щоCephObjectStoresу статусіConnected. -
Перевірте готовність
clusterSources. -
Окремо перевірте доступність файлової системи Ceph у проєкті
openshift-storage.
-
- Перевірки control-plane-console:
-
-
Виконайте вхід до Control Plane та переконайтеся, що можете бачите вміст розділів Реєстри та Керування Платформою.
-
Перейдіть до Керування Платформою та створіть адміністратора Платформи.
-
Зачекайте, доки Jenkins-пайплайн MASTER-Build-cluster-mgmt створить адміністратора та встановить права доступу у сервісі Keycloak. Виконайте вхід до Control Plane вже під щойно створеним адміністратором.
-
Створіть новий реєстр у Control Plane.
-
1.9. Налаштування відправлення повідомлень моніторингу
Налаштування сповіщень моніторингу (alerting notifications) налаштовується у компоненті Grafana. Для цього необхідно обрати канал зв’язку, куди надходитимуть сповіщення. Ми рекомендуємо використовувати чат-бот у Telegram.
|
Це рекомендоване базове налаштування сповіщень системи моніторингу. Вивести сповіщення можна з різних дашбордів. Більш просунуті налаштування виконуються адміністратором Платформи на власний розсуд. |
| Детальніше про функціональність дивіться на сторінці Налаштування сповіщень моніторингу Grafana. |
1.10. Налаштування базових бордів в Kibana
Для логування (журналювання) подій на Платформі використовуються компоненти EFK-стека (Elasticsearch, Fluentd, Kibana). EFK-стек відповідає за збір, обробку та візуалізацію журналів подій (логів), що сприяє прозорості та відстеженню стану системи.
Підсистема журналювання подій розгортається в окремому проєкті в OpenShift під назвою openshift-logging. Це дозволяє ізолювати ресурси, пов’язані з логуванням, від інших компонентів системи, що сприяє підвищенню безпеки та стабільності.
Для візуалізації журналів усіх додатків на платформі використовується Kibana, яка надає інтерактивний інтерфейс для аналізу логів та відстеження подій в системі.
| Детальніше див. на сторінках розділу Перегляд журналів подій Платформи (Kibana). |
1.11. Налаштування бекапів центральних компонент
Платформа підтримує два види резервного копіювання центральних (інфраструктурних) компонентів:
-
Ручне резервне копіювання (див. детальніше — Резервне копіювання та відновлення центральних компонентів).
-
Автоматичне резервне копіювання через встановлений розклад: (див. детальніше — Керування розкладом створення резервних копій центральних компонентів та часом їх зберігання).
Після створення резервної копії, середовище центральних компонентів можна відновити безпосередньо з такої копії.
1.12. Налаштування ключів цифрового підпису Платформи
Створення ключів та сертифікатів цифрового підпису відбувається під час розгортання платформи (див. детальніше — Необхідні елементи для розгортання Платформи).
Загальний опис ключів на Платформі доступний на сторінці: Налаштування ключів та сертифікатів цифрового підпису.
Ключі та сертифікати цифрового підпису можна оновлювати безпосередньо у процесі роботи з Платформою в інтерфейсі Control Plane (див. детальніше — Оновлення ключів та сертифікатів цифрового підпису для Платформи).
1.13. Налаштування та отримання дозволу для поштового сервера в AWS-середовищі
Адміністратор Платформи має спочатку налаштувати поштовий сервер. Це можна зробити, користуючись інструкцією на сторінці Налаштування внутрішнього SMTP-сервера.
В рамках процедури налаштування, критично важливим є Отримання дозволу для поштового сервера в AWS-середовищі. Це потрібно є для того, щоб забезпечити надійність та ефективність відправки електронних листів.
У випадку розгортання Платформи в AWS, за замовчуванням будь-який трафік з 25 порту (SMTP) заблокований.
Необхідно створити запит Request to remove email sending limitations до технічної підтримки AWS. Час розглядання запита — до 48 годин.
1.14. Налаштування обмежень доступу на мережевому рівні до адміністративних ендпоінтів Платформи
У розділі Керування Платформою консолі Control Plane адміністратор може задати CIDR для обмеження зовнішнього доступу заданим діапазоном для платформних та інфраструктурних компонентів (роутів).
| Детальніше про це див. на сторінці CIDR: Обмеження доступу до Платформних та реєстрових компонентів. |
1.15. Захист інфраструктури цільових оточень
За безпеку цільової інфраструктури несе відповідальність адміністратор оточення, згідно з відповідними організаційними політиками.
1.16. Оновлення компонентів
1.16.1. Спеціальні кроки для оновлення кластера Платформи
Окрім стандартної процедури оновлення, кожний реліз має свою специфіку щодо виконання спеціальних кроків, пов’язаних з оновленням компонентів Платформи.
| Розпочніть процес оновлення на сторінці Спеціальні кроки з оновлення, і вже в рамках виконання спеціальних кроків перейдіть до оновлення інфраструктурних компонентів. |
1.16.2. Оновлення інфраструктурних компонентів Платформи (Оновлення cluster-mgmt)
| Розпочніть процес оновлення на сторінці Спеціальні кроки з оновлення, і вже в рамках виконання спеціальних кроків перейдіть до оновлення інфраструктурних компонентів. |
Керування оновленнями інфраструктурних компонентів Платформи відбувається в адміністративній панелі керування Платформою та реєстрами Control Plane.
Оновлення відбувається за підходом GitOps.
| Детальніше про це див. на сторінці Оновлення інфраструктурних компонентів Платформи. |
1.17. Міграція реєстрів
Інколи потрібно перенести реєстр, його налаштування та ресурси з одного кластера на інший.
Міграція реєстру виконується з останньої резервної копії наявного реєстру та переноситься із кластера А до кластера В й відновлюється вже на цільовому кластері.
| Детальніше про міграцію див. у розділі Міграція. |
2. Підготовчі дії на рівні реєстрів
2.1. Рекомендації щодо формування команд підтримки реєстрів L1, L2, L3
- Обов’язкові пункти:
-
-
Обсяг підтримки:
-
Визначте обов’язкові рівні підтримки (L1, L1.5, L2, L3 тощо). Зверніть увагу на те, що кожний рівень вимагає окремого набору навичок та ресурсів.
-
Окресліть середовища, які підтримуються (Prod, Stage тощо). Команда повинна мати достатній досвід роботи у цих середовищах.
-
-
ITSM-система для відстеження запитів на підтримку. Рекомендуємо впровадити Jira Service Management від Atlassian (хмарне рішення).
-
Покриття часом (8*5, 16*5, чергування, календар свят і т.д.). Пам’ятайте про необхідність підтримки у неробочі години та святкові дні.
-
Підтримка мов. Ваша команда повинна вміти ефективно спілкуватися на потрібних мовах.
-
Очікувана кількість запитів. Це допоможе вам визначити потрібну кількість членів команди.
-
Основний часовий пояс для бізнесу. Це важливо для планування робочого часу команди.
-
Вимоги до SLA/SLO/OLA. Вони визначають очікувані рівні якості сервісу.
-
Канали комунікації (запити, телефонна лінія тощо). Команда повинна бути готова працювати з потрібними каналами комунікації.
-
Інструменти та технологічний стек. Ваша команда повинна володіти потрібними технологіями.
-
Кількість користувачів системи. Це також впливає на кількість потрібних членів команди.
-
- Додатково також зверніть увагу на наступні пункти:
-
-
Звіт про запити (tickets dump). Це допоможе вам краще зрозуміти потреби користувачів.
-
Розмір наявної команди (якщо є). Це допоможе вам оцінити, чи потрібно вам додаткові ресурси.
-
Залежності від команд третіх сторін. Це важливо для планування співробітництва та координації.
-
2.2. Створення реєстру та його первинна перевірка
Після Розгортання екземпляра реєстру, виконайте наступні первинні перевірки, щоб упевнитися, що усе встановлено та працює, як слід:
-
Отримайте логін та пароль для входу в OpenShift та Control Plane у адміністратора Платформи.
-
Перевірте, що в OpenShift розгорнувся простір імен (namespace) вашого реєстру. Ви маєте бачити лише свій проєкт реєстру.
-
Перевірте, що у ньому доступні усі поди та роути.
-
Перевірте логін до адміністративних інструментів реєстру та їх загальну доступність: Gerrit, Jenkins, Nexus та Admin Portal.
-
Виконайте вхід до Keycloak, перевіряємо, чи є там реєстрові реалми, зокрема:
-
-officer-portal -
-citizen-portal -
-admin -
-external-system
-
-
-
Перевірте доступ до Control Plane та виконайте вхід.
-
Перевірте, що бачите лише свій реєстр у Control Plane.
-
Перевірте, що можливо внести зміни до конфігурації реєстру. Наприклад, додайте адміністратора реєстру.
-
Перевірте, що коректно працює автентифікація.
-
Створіть посадову особу у Keycloak та виконуємо вхід до Кабінету посадової особи із КЕП.
-
Виконайте вхід до Кабінету отримувача послуг з КЕП.
-
| Також корисно буде ознайомитися зі сторінкою Перегляд та внесення змін до конфігурації реєстру. |
2.3. Оновлення компонентів реєстру
Керування оновленнями компонентів реєстру відбувається в адміністративній панелі керування Платформою та реєстрами Control Plane.
Оновлення відбувається за підходом GitOps, після Оновлення інфраструктурних компонентів Платформи (Оновлення cluster-mgmt).
| Детальніше про це див. на сторінці Оновлення компонентів реєстру. |
2.4. Спеціальні кроки для оновлення реєстру
Окрім стандартної процедури оновлення, кожний реліз має свою специфіку щодо виконання спеціальних кроків, пов’язаних з оновленням компонентів реєстру.
| Детальніше про це див. на сторінці Оновлення Платформи та реєстрів до версії 1.9.6: спеціальні кроки. |
2.5. Типові проблеми з автентифікацією користувачів реєстру та при підписанні бізнес-процесів
Розв’язати такі питання можна наступним чином:
-
Перевірте ключ цифрового підпису на https://id.gov.ua/sign.
-
Перевірте, що на подах DSO реєстру і проєкту
user-managementвстановлені останні сертифікати цифрового підпису.Якщо ключі та сертифікати застаріли або з якоїсь причини не працюють, їх необхідно оновити.
Детальніше про оновлення ключів та сертифікатів цифрового підпису читайте на сторінках:
-
Також типовою проблемою може бути наявність дублікатів. Наприклад, реалм
<registry-name>-officer-portalу Keycloak має двох користувачів з однаковими атрибутами.
2.6. Зміна режиму розгортання реєстру з production на development
|
Починаючи з релізу |
Режим розгортання (deployment mode) — це параметр, який вказує на те, в якому середовищі відбувається розгортання регламенту реєстру. Він дозволяє відрізнити виробниче середовище від середовища розробки, а також налаштувати конфігурацію відповідно до потреб кожного з них. Платформа реєстрів підтримує 2 режими розгортання: development та production.
| Детальніше про це див. на сторінці Налаштування режиму розгортання реєстру (deployment mode). |
2.7. Особливості розгортання регламенту в production-середовищі
- Структура регламенту:
- Розгортання регламенту:
- Зміна режиму розгортання регламенту:
- Що необхідно для початку роботи:
- Пайплайн публікації регламенту:
- Автоматична валідація при внесенні змін до регламенту:
- Кабінет адміністратора регламентів:
- Інші корисні документи:
2.8. Рекомендований алгоритм внесення змін до регламенту реєстру
Після розгортання реєстру адміністратором Платформи, реєстр матиме порожній репозиторій Gerrit із регламентом.
Внесення змін до регламенту з нуля або згодом, під час оновлення регламенту, процесуально не відрізняється й відбувається за GitOps-підходом.
Що таке GitOps-підхід?GitOps — це підхід до керування інфраструктурою та розгортання програмного забезпечення, який базується на використанні системи контролю версій Git. У GitOps-підході всі конфігураційні файли, описи інфраструктури та код програмного забезпечення зберігаються в репозиторії Git. Це означає, що будь-які зміни в інфраструктурі або програмному забезпеченні відбуваються через коміти до Git-репозиторію. |
Файли оновлюються в локальному середовищі, публікуються до віддаленого Gerrit-репозиторію. Пайплайн публікацій відстежує зміни у файлах директорій регламенту, і при git merge змін до майстер-гілки репозиторію, спрацьовує пайплайн публікацій Master-Build-registry-regulations, який збирає увесь код. Після виконання пайплайну, зміни набувають чинності, а регламент оновлюється до версії останнього коміту.
Можна оновлювати регламент використовуючи або просунутий підхід, або спрощений.
- Просунутий підхід
-
включає роботу з директоріями файлів, системою git та Gerrit через Git Bash консоль, або з іншими інструментами, а також використання Jenkins та ін.
Алгоритм внесення змін:
-
Клонуйте на локальну машину порожній Gerrit-репозиторій із регламентом реєстру.
-
Додайте до каталогу registry-regulations відповідні файли:
-
Створіть модель даних реєстру (data-model).
-
Змоделюйте бізнес-процеси (bpmn).
-
Змоделюйте UI-форми до бізнес-процесів (forms).
-
Визначте ролі для вашого реєстру (roles).
-
Визначте доступи до бізнес-процесів для відповідних ролей (bp-auth).
-
Визначте інші налаштування, передбачені регламентом вашого реєстру (сповіщення, витяги, глобальні змінні тощо).
-
-
Виконайте наступні команди:
git add --all
git commit -m "message commit"
git push refs/for/master
-
Пройдіть рецензування коду — Code Review. Спочатку має пройти автоматичний Jenkins процес перевірки MASTER-Code-review-registry-regulations, далі потрібно, щоб уповноважений адміністратор підтвердив внесення змін до регламенту.
-
Виконайте
git merge(злиття змін) доmaster-гілки Gerrit-репозиторію із регламентом реєстру.
-
- Спрощений підхід
-
передбачає використання зручного вебінтерфейсу адміністратора регламентів та його вбудованих можливостей.
Алгоритм внесення змін:
-
Увійдіть до Кабінету адміністратора регламентів.
-
Створіть нову версію-кандидат на внесення змін.
-
Додайте відповідні зміни:
-
Створіть модель даних реєстру (Таблиці).
-
Змоделюйте бізнес-процеси (Моделі процесів).
-
Змоделюйте UI-форми до бізнес-процесів (UI-форми).
-
Визначте інші налаштування, передбачені регламентом вашого реєстру.
-
-
Перейдіть на вкладку Огляд версії та натисніть
Застосувати зміни до майстер-гілки.Внаслідок цього створиться автоматичний запит на внесення змін до регламенту, який автоматично підтвердиться, зміни опублікуються в регламенті.
-
|
Детальніше про роботу з регламентом див. на сторінках: Інші корисні документи: |
2.9. Налаштування ключів та сертифікатів цифрового підпису реєстру
Створення ключів та сертифікатів цифрового підпису відбувається під час розгортання реєстру (див. Розгортання екземпляра реєстру).
Загальна інформація про типи ключів на Платформі реєстрів: Налаштування ключів та сертифікатів цифрового підпису
Оновлення ключів та сертифікатів цифрового підпису: Оновлення ключів та сертифікатів цифрового підпису для реєстру
2.10. Налаштування поштового сервера (SMTP-сервер)
Внутрішній SMTP-сервер — це компонент Платформи, призначений для відправлення нотифікацій кінцевим користувачам. Під час інсталяції Платформи, він розгортається у проєкті smtp-server.
| Адміністратор Платформи має спочатку налаштувати власне сам поштовий сервер (див. п. Налаштування та отримання дозволу для поштового сервера в AWS-середовищі). |
Згодом адміністратор реєстру зможе налаштувати підключення до такого сервера для відправлення поштових повідомлень користувачам. Це можна зробити в інтерфейсі Control Plane, скориставшись інструкцією на сторінці Налаштування підключення до поштового сервера.
2.14. Конфігурація реєстру під навантаження
Кожен реєстр має свої специфічні задачі, логіку роботи й налаштування, а звідси — й набір певних сервісів, які залучені для виконання цих задач більшою або меншою мірою.
Відповідно до навантаження на певний реєстр, а це напряму залежить від кількості запитів від активних користувачів, сервіси реєстру потребують певної кількості ресурсів та можуть бути розгорнуті в одному та більше екземплярах.
|
Для прикладу, під час обслуговування 1500 активних користувачів протягом 1 години, умовний реєстр повинен мати приблизно наступну конфігурацію: Конфігурація горизонтального масштабування реєстру
|
| Ознайомтеся із детальними звітами та параметризацією тестування навантаження у розділі Звіти продуктивності системи. |
Залежно від потреб вашого реєстру, можливо змінювати конфігурації певних сервісів, зокрема ви можете:
- Масштабувати ресурси вертикально
-
Зробити це можна двома способами:
-
(Основний шлях) В адміністративній панелі Control Plane, у розділі керування ресурсами для сервісів.
Детальніше про це ви можете дізнатися на сторінці Керування ресурсами реєстру. -
(Додатковий шлях) В OpenShift-консолі:
Цей підхід дозволяє швидко додати ресурси до певних сервісів, але з часом налаштування будуть скинуті до тих, що зазначені в Helm-чарті. -
Оберіть проєкт із вашим реєстром > Workloads > Deployments > Відкрийте налаштування сервісу > YAML.
-
У розділі
spec.containers.resourcesви можете встановити необхідні параметри конфігурації для CPU та memory. -
У розділі
spec.containers.resources.envви можете визначити змінні оточення для ваших застосунків, як-тоJAVA_OPTS, змінні для Ceph тощо.
-
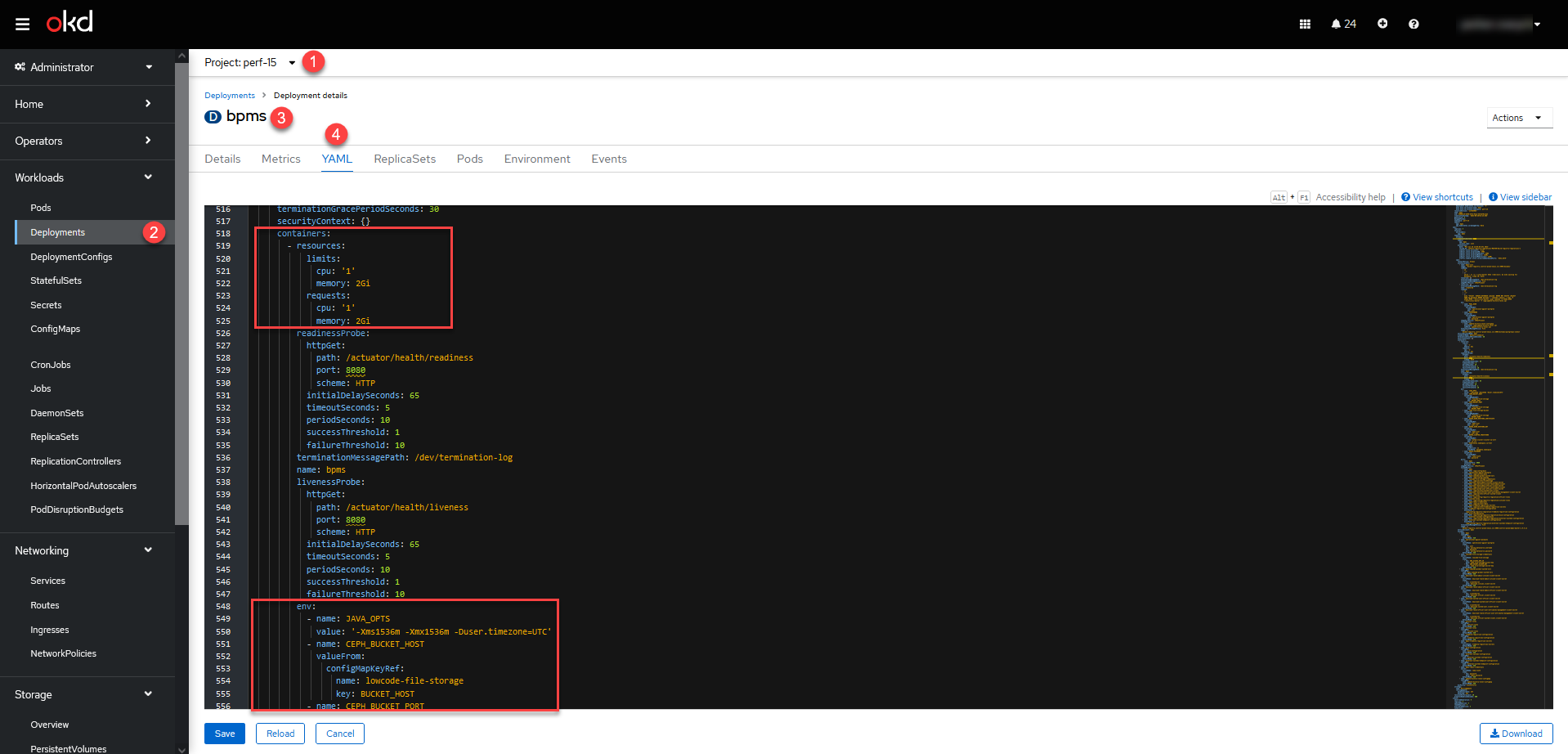
-
- Масштабувати ресурси горизонтально
-
Горизонтальне масштабування можна виконати внаслідок збільшення кількості реплік певних сервісів.
-
Наразі масштабувати горизонтально так:
Цей підхід дозволяє швидко додати кількість реплік для бажаних сервісів, але з часом налаштування будуть скинуті до тих, що зазначені в Helm-чарті. -
Оберіть проєкт із вашим реєстром > Workloads > Deployments > Відкрийте налаштування сервісу > YAML.
-
У розділі
spec.replicasви можете встановити потрібну кількість реплік для обраного сервісу.Приклад. Горизонтальне масштабування сервісу bpms до трьох реплікspec: replicas: 3
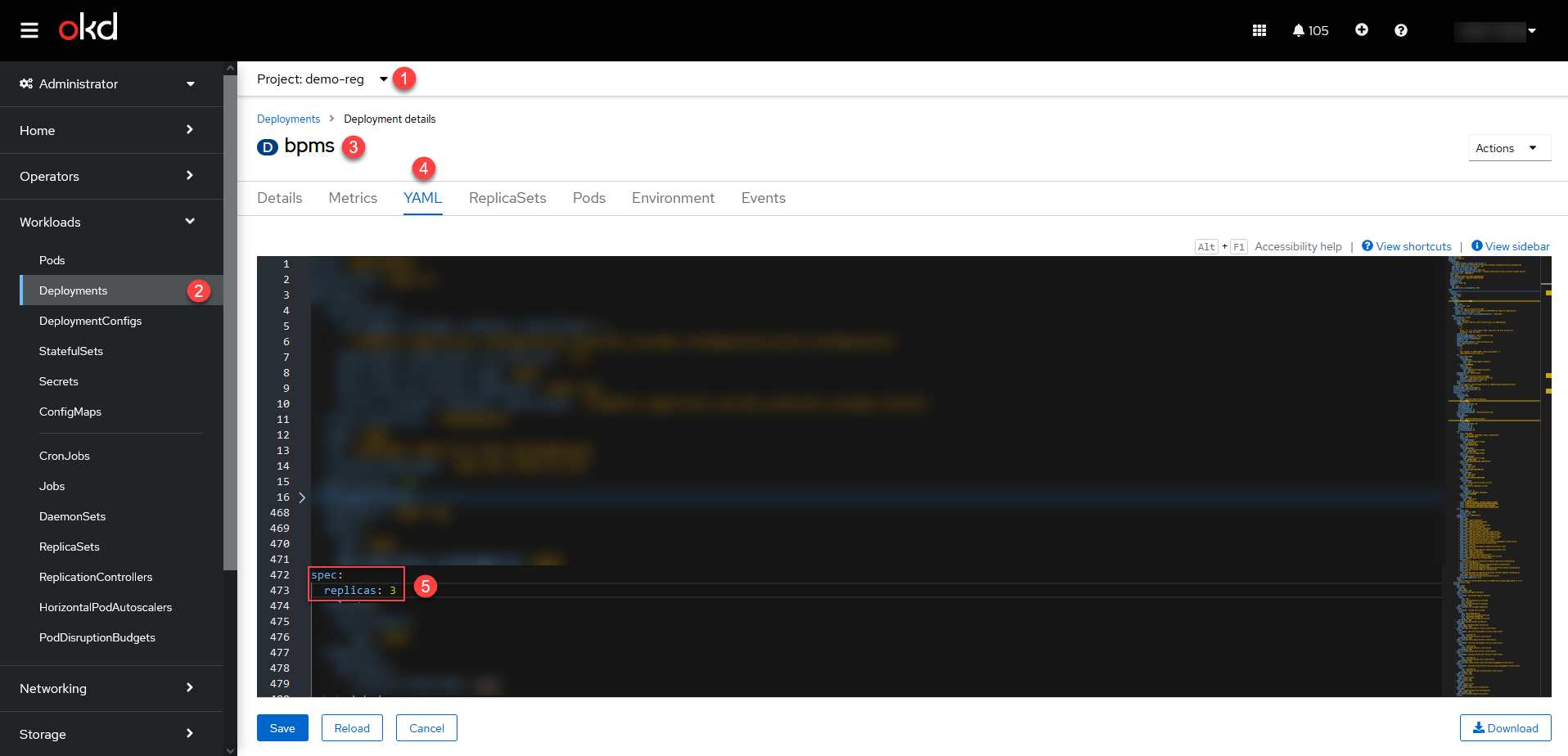
-
Налаштувати горизонтальне масштабування автоматизовано (Horizontal Pod Autoscaler) буде можливе у розділі Ресурси реєстру адміністративної панелі Control Plane у наступних релізах, починаючи з 1.9.7. -
2.15. Планування місця для сховищ реєстру
Компоненти реєстру зберігаються у томах сховища Ceph. Конфігурації доступного місця на дисках для таких компонентів доступні через OpenShift-консоль, у розділі Storage > PersistentVolumeClaims, у проєкті вашого реєстру.
Розмір дисків можна змінювати відповідно ваших потреб. Однак існує три підходи для розширення місця на дисках для різних сервісів реєстру:
- I.Expand PVC
-
Цей підхід релевантний для більшості компонентів реєстру та є найпростішим.
Розширити місце на дисках для таких компонентів можна через OpenShift-консоль, у розділі Storage > PersistentVolumeClaims >
Expand PVC, у відповідному проєкті (namespace) реєстру. Наприклад,demo-reg.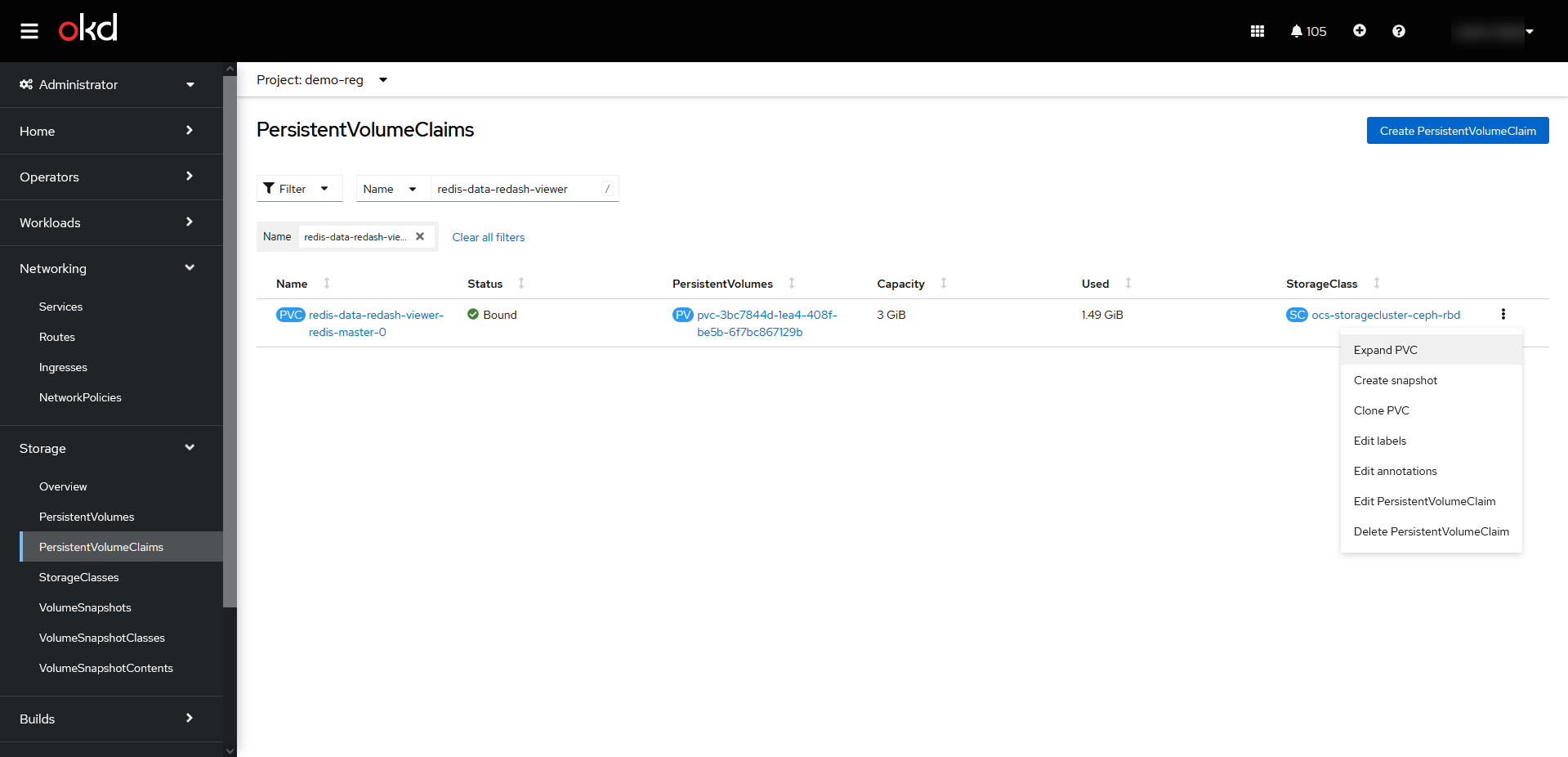 Зображення 3. Розширення місця для компонента redis-data-redash-viewer
Зображення 3. Розширення місця для компонента redis-data-redash-viewer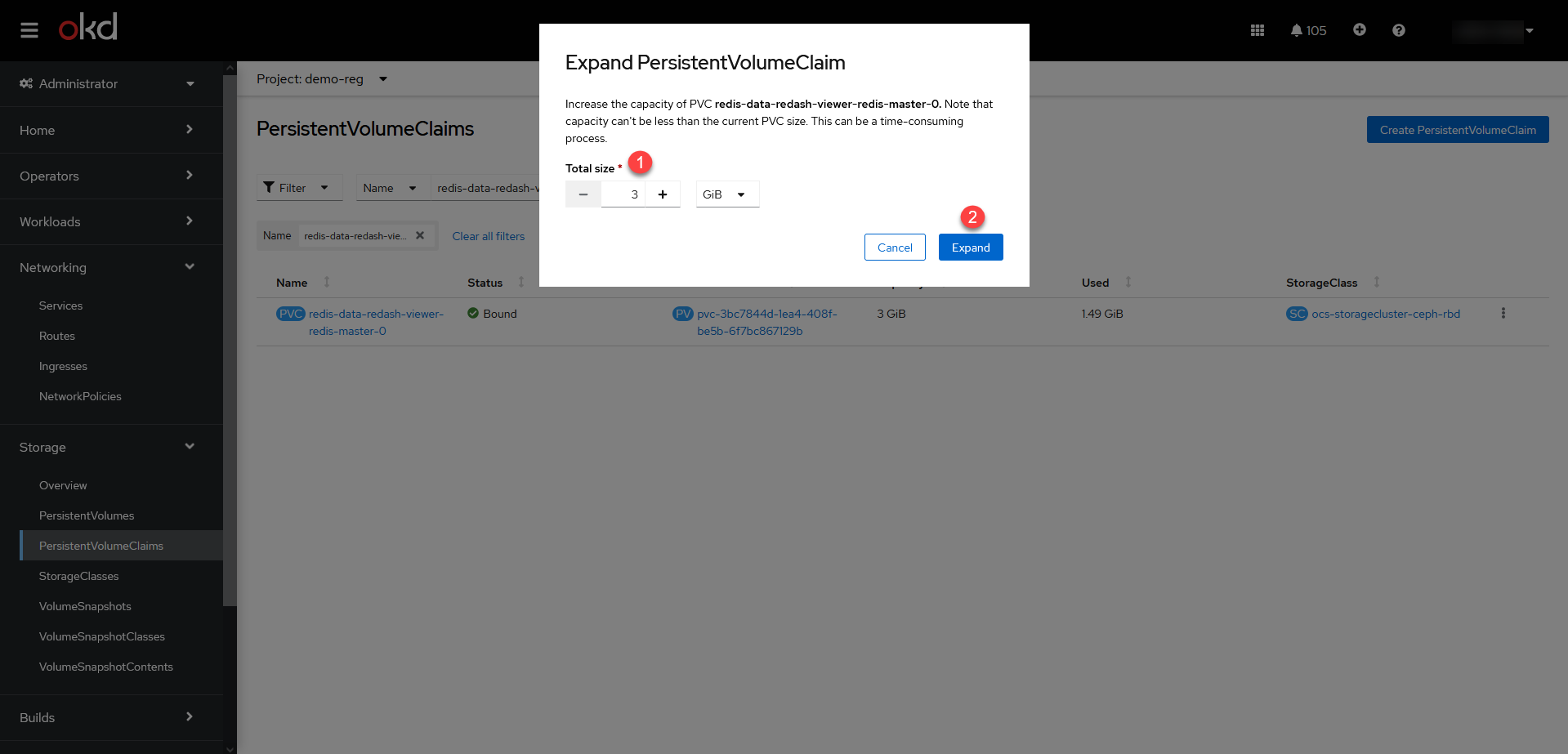 Зображення 4. Розширення місця для компонента redis-data-redash-viewer
Зображення 4. Розширення місця для компонента redis-data-redash-viewer - II.Expand PVC + deploy-templates/value.yaml
-
Цей підхід стосується лише деяких сервісів по роботі з даними, зокрема
crunchyPostgresтаkafka.Розширити місце на дисках для таких компонентів можна наступним чином:
-
(Опціонально). Відкрийте OpenShift-консоль та відкрийте Storage > PersistentVolumeClaims у відповідному проєкті (namespace) реєстру. Наприклад,
demo-reg. Далі натиснітьExpand PVC. -
У центральному Gerrit Платформи знайдіть репозиторій із вашим реєстром.
-
Оберіть
master-гілку та відкрийте конфігураційний файл deploy-templates/values.yaml.-
Для
crunchyPostgresвстановити розмір сховища можна у параметріglobal.crunchyPostgres.storageSize. -
Для
kafkaвстановити розмір сховища можна у параметріglobal.kafkaOperator.storage.kafka.size.
Розширення місця для компонентів crunchyPostgres та kafkaglobal: crunchyPostgres: storageSize: 50Gi kafkaOperator: storage: kafka: size: 20Gi -
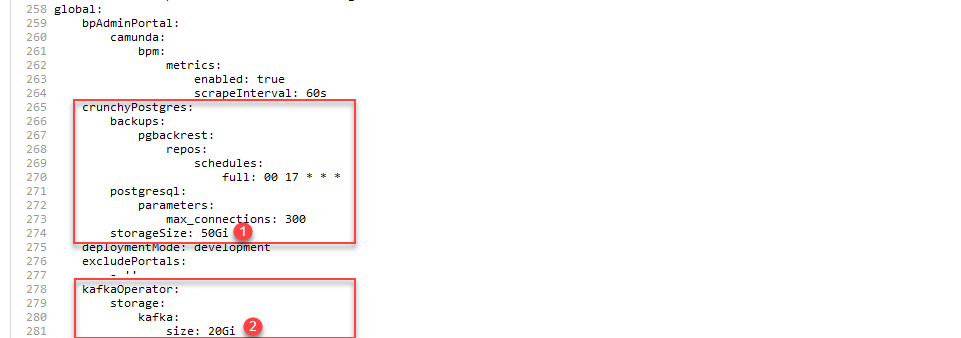 Зображення 5. Розширення місця для компонентів crunchyPostgres та kafka
Зображення 5. Розширення місця для компонентів crunchyPostgres та kafka -
- III.Expand PVC + deploy-templates/value.gotmpl
-
Цей підхід стосується лише деяких основоположних сервісів, зокрема для реєстрових
gerrit,jenkins,nexusтаregistryRegulationManagement.Розширити місце на дисках для таких компонентів можна наступним чином:
-
(Опціонально). Відкрийте OpenShift-консоль та відкрийте Storage > PersistentVolumeClaims у відповідному проєкті (namespace) реєстру. Наприклад,
demo-reg. Далі натиснітьExpand PVC. -
У центральному Gerrit Платформи знайдіть репозиторій із потрібним реєстром.
-
Оберіть
master-гілку та відкрийте конфігураційний файл deploy-templates/values.gotmpl.-
Для
gerritвстановити розмір сховища можна у параметріgerrit.storage.size.Приклад. Розширення місця для компонента gerrit реєструgerrit: storage: size: 10Gi -
Для
jenkinsвстановити розмір сховища можна у параметріjenkins.storage.size.Приклад. Розширення місця для компонента jenkins реєструjenkins: storage: size: 30Gi -
Для
nexusвстановити розмір сховища можна у параметріnexus.storage.size.Приклад. Розширення місця для компонента nexus реєструnexus: storage: size: 150Gi -
Для
registryRegulationManagementвстановити розмір сховища можна у параметріregistryRegulationManagement.volume.size.Приклад. Розширення місця для компонента registryRegulationManagementregistryRegulationManagement: volume: size: 20Gi
-
-
Кожний сервіс запускається із налаштуваннями розміру дисків за замовчуванням. Ви як адміністратор можете залишити ці налаштування, або якщо ви чітко знаєте, що виділеного розміру дисків недостатньо для ваших потреб, тоді томи можна розширити одразу. Рекомендоване значення для збільшення місця на диску +50%. Наприклад, розмір диска для компонента jenkins за замовчування — 10Gi. Тоді для початку ви можете збільшити місце до 15Gi.
|
|
Якщо ви не впевнені, який підхід по збільшенню місця у сховищах використати, то почніть із першого — розширте місце через Далі запустіть Jenkins-пайплайн розгортання реєстру MASTER-Build- |
|
Також рекомендуємо ознайомитися з описом налаштувань файлової системи на сторінках: |
2.16. Отримання доступу для L2 до системи сповіщень, моніторингу та логування у реєстрі
Надайте права доступу до компонента cluster-mgmt у розділі Керування Платформою на Control Plane. Все, що потрібно зробити — це створити адміністратора Платформи, й відповідні права автоматично додадуться.
|
Це правило застосовується тільки у тому випадку, якщо бізнес-вимоги дозволяють інженерам L2 бути адміністраторами Платформи. Зазвичай це буде нормою, але можуть бути ситуації, коли на одній Платформі для різних реєстрів існують окремі L2. У таких випадках можуть виникнути питання щодо обмеження доступу. |
| Детальніше про це див. сторінку Створення адміністраторів Платформи. |
2.17. Налаштування бекапів
2.17.1. Налаштування бекапів реєстру
Платформа підтримує два види резервного копіювання компонентів реєстру:
-
Ручне резервне копіювання (див. детальніше — Резервне копіювання та відновлення екземпляра реєстру)
-
Автоматичне резервне копіювання через встановлений розклад: (див. детальніше — Керування розкладом резервного копіювання реєстру)
Після створення резервної копії, реєстр можна відновити безпосередньо з такої копії.
2.17.2. Налаштування бекапів реплікації файлів реєстру
Платформа надає вбудований механізм реплікації даних між S3-сумісними сховищами.
Реплікація полягає в автоматичному копіюванні даних з одного бакета до іншого, що може бути корисним, наприклад, для створення резервних копій даних в інших географічних регіонах, що забезпечує високу доступність та надійність.
Реєстр містить дані, які є необхідними для бізнес-процесів, зокрема тимчасові дані, історія виконання процесів тощо. Ці дані зберігаються у вигляді ObjectBucketClaim (obc) в S3-бакетах. Реплікація цих бакетів відбувається автоматично. Ви можете налаштувати резервне копіювання для таких реплікацій через адміністративну панель Control Plane.
| Детальніше про це див. на сторінці Резервне копіювання реплікацій об’єктів S3. |
2.18. Інтеграція з id.gov.ua та використання стилізованого віджета
-
Особливості налаштування автентифікації через ID.GOV.UA див. на сторінці Налаштування автентифікації надавачів послуг.
-
Особливості автентифікації через ID.GOV.UA користувачами див. на сторінці Автентифікація користувачів реєстру.
-
Посилання на офіційне джерело ID.DOV.UA: http://id.gov.ua.
2.19. Визначення порядку надання доступу посадовим особам
-
Створіть посадову особу. Це можна зробити вручну або через імпорт із CSV-файлу.
Посадова особа створюється у сервісі Keycloak з обов’язковими для автентифікації атрибутами:
-
drfo— код РНОКПП (ідентифікаційний номер;) -
edrpou— код ЄДРПОУ; -
fullName— Прізвище, ім’я та по батькові.
Також можна додати будь-які інші опціональні атрибути, передбачені вимогами реєстру.
-
-
Додайте ролі у Keycloak для посадової особи, зокрема системну роль
officerта інші передбачені логікою реєстру ролі. -
Ці самі ролі визначте на рівні Gerrit-репозиторію з регламентом реєстру у файлі roles/officer.yml.
-
Налаштуйте доступи до певних бізнес-процесів для відповідних ролей у файлі bp-auth/officer.yml.
2.22. Рекомендації щодо уникнення "покинутих" бізнес-процесів користувачами
"Покинуті" або застарілі бізнес-процеси (abandoned business processes) в контексті Camunda Engine належать до бізнес-процесів, які були розпочаті, але не були завершені або виконані до кінця. Це може статися у випадках, коли бізнес-процес переривається, скасовується або припиняється з певної причини, зокрема помилка або виняток тощо.
Є декілька способів розв’язання цієї проблеми:
-
Уникайте "покинутих" процесів. Цього можна досягти через правильне моделювання, зокрема виходом є призначення таймерів завершення процесу (Timer Boundary Event) типу Duration на кожній користувацькій задачі (User Task).
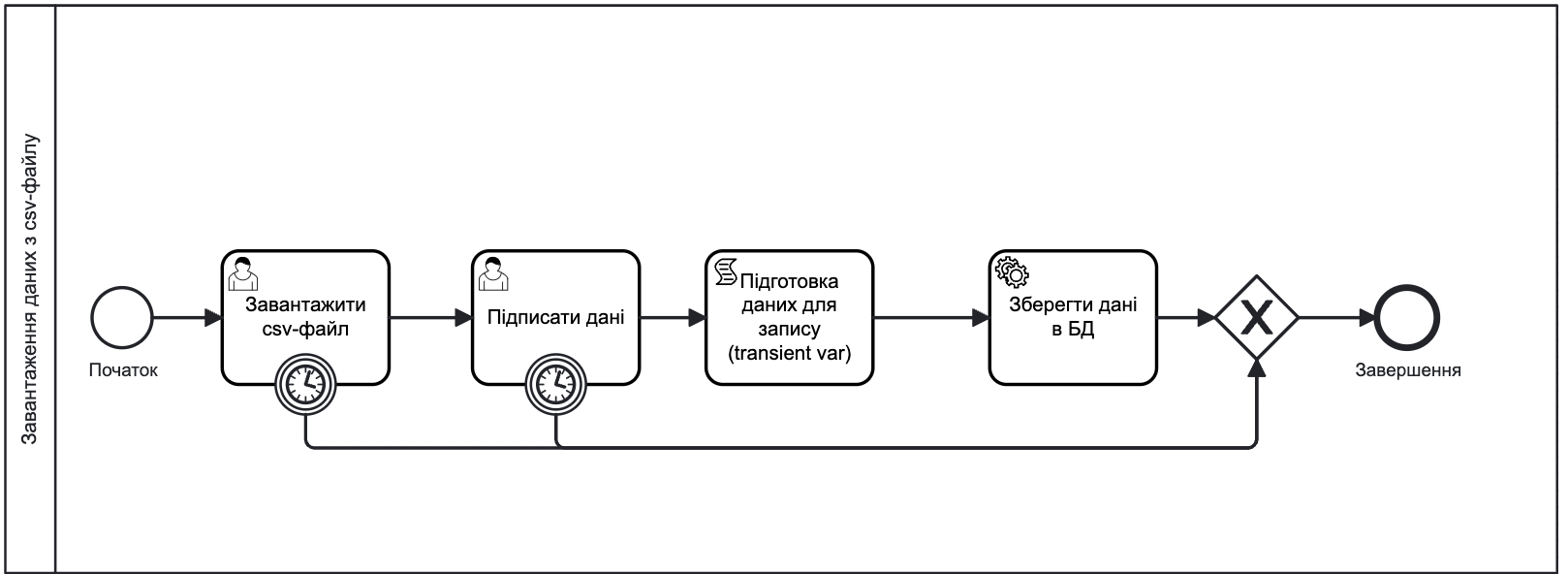 Зображення 6. Бізнес-процес із таймером завершення
Зображення 6. Бізнес-процес із таймером завершенняЗагальна рекомендація: моделювати таймер більш як на 14 днів, адже логи бізнес-процесів за замовчуванням зберігаються в Elastic Search протягом 14 днів і згодом видаляються. Після видалення логів буде неможливо ідентифікувати помилку. -
Детальніше про таймери дивіться на сторінці Подія «Таймер».
-
Також про налаштування таймерів можна переглянути на сторінці Запуск бізнес-процесу за таймером
-
-
Якщо вже сталося так, що деякі процеси не завершилися, скористайтеся інструментом для моніторингу та адміністрування бізнес-процесів — Business Process Administration Portal (Camunda Cockpit). Через його інтерфейс можна по-одному видалити усі такі процеси.
Детальніше про це див. на сторінці Адміністрування бізнес-процесів у Camunda Cockpit.
2.23. Налаштування рейт-лімітів
API рейт-ліміти дозволяють обмежити кількість HTTP-запитів до сервісу чи роуту за вказаний період часу.
Механізм рейт-лімітів реалізований на базі Rate-Limiting-плагіну для Kong API Gateway. Адміністратор безпеки із відповідними правами доступу може налаштувати необхідні значення лімітів.
| Детальніше про це див. на сторінці API Рейт-ліміти: обмеження кількості запитів за одиницю часу. |
2.24. Налаштування обмежень доступу на мережевому рівні до компонентів реєстру (CIDR)
У розділі Реєстри консолі Control Plane адміністратор може задати CIDR для обмеження зовнішнього доступу заданим діапазоном до адміністративних ендпоінтів реєстру, а також Кабінетів отримувачів та надавачів послуг.
| Детальніше про це див. на сторінці Обмеження доступу до компонентів реєстру. |
2.25. Обмеження доступу на рівні IP до SOAP-роутів ШБО "Трембіта"
Ви можете регулювати доступ до SOAP API-інтерфейсів реєстру через адміністративну панель Control Plane.
| Детальніше про це див. на сторінці Обмеження доступу на рівні IP до SOAP-роутів ШБО "Трембіта". |
2.26. Налаштування власних DNS-імен
Ви можете налаштувати власні DNS-імена окремо для:
-
Кабінету користувача —
officer-portal; -
Кабінету отримувача послуг —
citizen-portal; -
Сервісу автентифікації та авторизації —
keycloak:-
встановіть власне DNS на рівні керування Платформою;
-
використовуйте визначені DNS у реєстрах.
-
| Детальніше про це див. на сторінці Налаштування власних DNS-імен. |
2.27. Додавання нових користувачів (через Keycloak та імпорт)
Ви можете додавати нових користувачів у системі декількома способами, зокрема:
-
Вручну, по-одному, в інтерфейсі Keycloak: Створення окремого користувача та надання прав доступу.
-
Масово, завантаженням через СSV-файл: Імпорт користувачів через файл та надання прав доступу
2.28. Призначення адміністраторів Платформи та реєстру
Спочатку автентифікуйтеся за допомогою системного користувача KubeAdmin та створіть адміністратора Платформи. Надалі цей адміністратор зможе самостійно додавати нових адміністраторів Платформи через інтерфейс Control Plane.
| Детальніше про це див. на сторінці Створення адміністраторів Платформи. |
Після цього адміністратор Платформи зможе створити реєстр та додати в ньому першого адміністратора. Надалі такий адміністратор зможе самостійно додавати нових адміністраторів реєстру через інтерфейс Control Plane.
| Детальніше про це див. на сторінці Створення адміністраторів реєстру. |
2.29. Розгортання геосервера та робота з геоданими у реєстрі
| Потрібно лише для реєстрів, які передбачають роботу із геопросторовими даними. |
Адміністратори реєстрів та розробники регламенту мають змогу налаштовувати роботу із геоданими.
У центрі рішення лежить компонент Geoserver — сервер із відкритим кодом, який дозволяє отримувати дані з БД у вигляді GeoJSON.
| Детальніше про це див. на сторінці Робота з геоданими у реєстрі. |
2.30. Первинне завантаження та дозавантаження даних до системи
Первинне завантаження/дозавантаження даних до БД можливе через процедуру на рівні моделювання структур даних: Первинне завантаження даних.
|
3. Рекомендації щодо нефункціонального тестування реєстрів на платформі
3.1. Тестування продуктивності
Тестування продуктивності Платформи проводиться на базі потужностей «EPAM» під конкретний реліз із використанням попередньо визначеної конфігурації кластера Openshift, окремо для кожного розгорнутого реєстру із певною кількістю активних користувачів при плановому повному навантаженні в робочий час.
Тестування продуктивності виконується інструментом Carrier — комплексним інструментом, що допомагає вимірювати, аналізувати й оптимізувати продуктивність роботи сервісів Платформи та реєстрів, які на ній розгорнуті.
| Детальніше про результати тестів ви можете дізнатися у розділі Звіти продуктивності системи. |
3.2. Тестування безпеки
Платформа реєстрів будується на основі методології безпечної розробки програмного забезпечення DevSecOps, відповідно до якої виконуються автоматичні перевірки безпеки на наявність відомих вразливостей. На регулярній основі проводиться тестування безпеки, зокрема тестування на проникнення (penetration testing), моделювання загроз (threat modeling) та автоматизоване сканування (automated scanning).
| Детальніше про тестування безпеки Платформи читайте на сторінці Тестування безпеки. |
4. Контрольний список для запуску публічного сервісу
|
Цей перелік пов’язаний насамперед із запуском публічного сервісу на основі реєстру та взаємодії із зовнішніми системами, такими як Дія (мобільний застосунок), Дія (адміністративний портал) та ін. Варто зазначити, що цей перелік не є вичерпним і може бути доповнений за потреби. Крім того, цей перелік, у тій чи іншій формі, може бути використаний для формування контрольного списку задач перед безпосереднім запуском реєстру, розробленого на Платформі. |
- 1.Функціональність:
-
-
Перевірте, що всі ключові функції та можливості сервісу працюють так, як це задумано.
-
Протестуйте усі взаємодії користувачів та процеси роботи, щоб забезпечити зручний досвід користувача (UAT-Beta).
-
Проведіть детальне функціональне тестування, щоб виявити усі вразливості та помилки.
-
- 2.Продуктивність:
-
-
Розрахуйте можливий потік запитів для вимог до тестування навантаження: перші дні після запуску, протягом періоду звичайної роботи.
-
Проведіть тестування навантаження, щоб оцінити, як сервіс впорається з великими користувацькими навантаженнями та одночасними запитами.
-
Перевірте час відповіді та переконайтеся, що сервіс відповідає вимогам до продуктивності.
-
Оптимізуйте продуктивність системи та масштабованість для обробки майбутнього зростання.
-
- 3.Безпека:
-
-
Проведіть комплексне тестування безпеки, включаючи тестування на проникнення та оцінку вразливостей.
-
Застосуйте відповідні заходи безпеки, такі як шифрування, аутентифікація та контроль доступу.
-
Забезпечте відповідність відповідним регулятивам щодо захисту даних та конфіденційності.
-
- 4.Сумісність:
-
-
Протестуйте сервіс на різних браузерах, операційних системах та пристроях.
-
Перевірте, що сервіс правильно працює та відображається на різних платформах.
-
Забезпечте сумісність з технологіями для людей з особливими потребами для забезпечення доступності.
-
- 5.Використання та досвід користувача:
-
-
Проведіть тестування на зручність використання, щоб зібрати відгуки користувачів та виявити всі проблеми з їх зручністю.
-
Забезпечте інтуїтивно зрозумілу навігацію, чіткі інструкції та зручний для користувача дизайн.
-
Врахуйте відгуки користувачів для покращення загального досвіду користувача.
-
- 6.Доступність:
-
-
Переконайтеся, що ви виконуєте вимоги до стандартів доступності, щоб гарантувати можливість використання сервісу особами з обмеженими можливостями.
-
Перевірте сумісність з адаптивними технологіями, такими як зчитувачі екрана та навігація за допомогою клавіатури.
-
- 7.Управління даними:
-
-
Застосуйте правильні практики управління даними, включаючи зберігання даних, резервне копіювання та плани відновлення після аварій.
-
Забезпечте цілісність даних, безпеку та заходи щодо конфіденційності.
-
Дотримуйтесь відповідних регулятивів щодо захисту даних.
-
- 8.Документація та підтримка:
-
-
Підготуйте посібники для користувачів, часто задавані питання (FAQs) та документацію, щоб допомогти користувачам зрозуміти та використовувати сервіс.
-
Забезпечте канали підтримки, такі як служби допомоги або онлайн-підтримка, для розгляду запитів та проблем користувачів.
-
- 9.Навчання:
-
-
Надайте навчання персоналу уряду та адміністраторам, відповідальним за керування сервісом.
-
Переконайтеся, що вони глибоко розуміють функціональність та процеси сервісу.
-
- 10.Юридичні та відповідності:
-
-
Забезпечте відповідність відповідним законам, нормам та стандартам.
-
Розгляньте вимоги щодо ліцензування, права інтелектуальної власності та будь-які юридичні зобов’язання, пов’язані з сервісом.
-
- 11.Моніторинг продуктивності та аналітика:
-
-
Використовуйте інструменти моніторингу та аналітики для відстеження продуктивності сервісу.
-
Моніторинг поведінки користувачів, використання системи та ключових показників продуктивності для виявлення областей для поліпшення.
-
- 12.Комунікація та план запуску:
-
-
Розробіть всеосяжний план комунікації та запуску для інформування зацікавлених сторін та користувачів про сервіс.
-
Координуйте дії з відповідними урядовими органами, відомствами та каналами медіа для успішного запуску.
-
Заплануйте необхідні ресурси (L1-L3) в усіх командах, що беруть участь у процесі розробки та підтримки, до дня запуску, щоб бути готовими до непередбачених ситуацій.
-
Проведіть комунікацію з усіма командами перед запуском, щоб подвійно перевірити готовність до запуску.
-
5. Засвоєні уроки
5.1. Помилки "Out-of-memory" у Java-сервісах
- Виникнення проблеми:
-
Два Java-сервіси,
bp-webservice-gatewayтаbpms, постійно перезавантажуються OpenShift через помилки "Out-of-Memory" (OOM).bp-webservice-gatewayобробляє вхідні запити з Trembita (Diia), тоді якbpmsвиконує бізнес-процеси, що надходять від відповідальних осіб таbp-webservice-gateway(Diia). - Основна причина:
-
Пам’ять, що виділяється для використання non-heap, виявилася недостатньою відповідно до поточного навантаження.
- Деталі:
-
-
bp-webservice-gateway:-
Heap:
512MB(Xms=Xmx) -
Загальний ліміт контейнера:
768MB(±805MB) (Request=Limit)
-
-
bpms:-
Heap:
1536MB (`Xms=Xmx) -
Загальний ліміт контейнера:
2GB(±2146MB) (Request=Limit)
-
-
- Розв’язання проблеми:
-
Загальні обмеження для контейнерів були кориговані, щоб відповідати потребам.
-
bp-webservice-gateway: встановіть новий загальний ліміт контейнера:1GB(Request=Limit) -
bpms: встановіть новий загальний ліміт контейнера:3GB(Request=Limit)
-
- Довгострокова стратегія:
-
-
Адаптація скриптів із тестування продуктивності для відтворення схожої проблеми.
-
Перегляд параметрів запитів/лімітів пам’яті для
bp-webservice-gatewayтаbpms.
-
5.2. Велике навантаження на процесор у Java-сервісах
Цей прогноз може допомогти вашій команді розробити стабільнішу систему, адаптовану до потенційного зростання навантаження на CPU.
- Виникнення проблеми:
-
Кожна репліка
bpmsпочала використовувати більше ніж 1 CPU, що свідчить про зростання потреби в обробці даних. - Основна причина:
-
Загальна кількість вхідних запитів значно зросла після запуску відповідного сервісу (
eReconstruction) в додатку Diia. - Розв’язання проблеми:
-
Сервіс
bpmsбуло масштабовано до 4-х реплік. - Довгострокова стратегія:
-
Не застосовується.
5.3. Тайм-аут з’єднання з базою даних у Java сервісах
Враховуючи наступні кроки, ваша команда зможе краще адаптувати систему для подальшої роботи з базою даних.
- Виникнення проблеми:
-
Виявлено більше ніж 100 тайм-аутів з’єднань із базою даних на панелі Spring Boot Grafana для сервісів
bpmsтаregistry-rest-api. - Основна причина:
-
-
BPMS тримає з’єднання протягом усього виконання бізнес-процесу, що може призвести до тайм-ауту з’єднання із базою даних для запитів у черзі. Аналіз сервісу
bpmsбув проведений у розділі Доступність Redis. -
У
registry-rest-apiпередбачені значення тайм-ауту з’єднання становлять 4 секунди, а пул з’єднань — 10. Однак, щось утримує з’єднання довше, ніж 4 секунди. Аналіз сервісуregistry-rest-apiбув проведений у розділі Повільні SQL-запити до бази даних.
-
- Розв’язання проблеми:
-
-
Загальна кількість доступних з’єднань із базою даних була збільшена.
-
Пул з’єднань в BPMS був збільшений.
-
Сервіс
registry-rest-apiбуло масштабовано до 5 реплік.
-
- Довгострокова стратегія:
-
Додати можливість конфігурувати тайм-аут з’єднання та пул з’єднань для
registry-rest-apiчерез зовнішнє налаштування.
5.4. Команда OOM у Redis не дозволена
- Виникнення проблеми:
-
В логах
bp-webservice-gatewayбула виявлена помилка:Це сталося під час обробки вхідних запитів від Trembita. - Основна причина:
-
Помилка
вказує на те, що Redis було налаштовано з обмеженням пам’яті, і цей ліміт було досягнуто. Ця помилка означає, що пам’ять Redis переповнена, і він не може зберігати нові дані, доки пам’ять не буде звільнена або ліміт пам’яті не буде збільшений. - Розв’язання проблеми:
-
Обмеження пам’яті в Redis було збільшено.
- Довгострокова стратегія:
-
Налаштувати обмеження пам’яті Redis заздалегідь.
5.5. Повільні SQL-запити до бази даних
Наступні прогнози та заходи допоможуть вашій команді покращити швидкість обробки даних та відповідність запитів, що забезпечить кращу продуктивність та стабільність системи.
- Виникнення проблеми:
-
У логах бази даних було зафіксовано численні запити, які виконувалися довше ніж 1 секунда, деякі запити навіть тривали до 10 секунд. Це свідчить про наявність повільних запитів у системі.
- Основна причина:
-
Система зазнала каскадного ефекту внаслідок обробки складних SQL-запитів до таблиць та представлень, що не мали потрібних індексів. Це спричинило ряд проблем, зокрема:
-
Повільні SQL-запити: неналежна індексація призвела до неоптимального виконання SQL-запитів, що своєю чергою викликало значні затримки їх обробки.
-
Тайм-аут з’єднання для вхідних запитів у черзі: довгий час виконання повільних SQL-запитів призводив до тайм-аутів з’єднань для інших вхідних запитів, що очікували у черзі.
-
Помилки
HTTP 500на клієнті (Кабінеті посадової особи або BPMS-сервісі): у результаті тайм-аутів з’єднань, клієнти, такі як Кабінеті посадової особи або BPMS, отримували помилкиHTTP 500, що вказує на проблеми із сервером. -
Довгі HTTP-запити від BPMS: повільні SQL-запити також впливали на BPMS-сервіс, що призводило до довших HTTP-запитів та збільшення часу виконання бізнес-процесів.
-
Camunda тримає з’єднання із базою даних протягом тривалого часу: через тривале виконання SQL-запитів, Camunda, система управління робочими процесами, яку використовує BPMS, тримала з’єднання із базою даних протягом довшого часу.
-
- Розв’язання проблеми:
-
Було створено індекси для всіх повільних запитів, які використовувалися.
- Довгострокова стратегія:
-
Додати створення індексів при моделюванні структур даних вашого реєстру.
5.6. Доступність Redis
- Виникнення проблеми:
-
Redis зіткнувся з проблемою повільної відповіді, що призводило до затримок в обробці вхідних запитів, тривалістю до 10 секунд. Це викликало провал тестів готовності для Redis, що сигналізувало про його неспроможність ефективно обробляти вхідні запити. Щобільше, навіть спроба входу в Redis через командний рядок (CLI) призводила до значних затримок, займаючи декілька секунд на виконання.
- Основна причина:
-
У BPMS є метод для очищення даних форми в Redis після завершення виконання бізнес-процесу. Однак цей метод використовує команду “keys”, яка має складність
O(n)для пошуку необхідних ключів Redis для видалення. Це стає звичайною причиною затримок, коли в Redis зберігається значна кількість даних, як у цьому випадку зі 100 тис. записів.Через неефективність команди “keys”, пошук потрібних ключів Redis для видалення займає більше часу, що призводить до збільшення затримки. В результаті, коли багато з’єднань стикаються з тайм-аутами, метод очищення не завершується успішно. Внаслідок цього в Redis залишаються додаткові непотрібні записи, що далі впливає на його продуктивність та збільшує об’єм зберігання.
- Розв’язання проблеми:
-
Було створено індекси для всіх повільних запитів, які використовувалися.
- Довгострокова стратегія:
-
Додати створення індексів при моделюванні структур даних вашого реєстру.