Завдання 9. Моніторинг метрик компонентів реєстру (Grafana)
1. Мета завдання
- Виконання цього завдання має на меті:
-
-
Отримати навички роботи з Grafana для моніторингу метрик компонентів реєстру.
-
2. Процес виконання завдання
2.1. Ознайомлення з наявними Dashboards
-
Перейдіть до швидких посилань та оберіть Grafana.
-
Оберіть Sign in with OAuth.
-
Автентифікуйтеся як адміністратор цього реєстру та натисніть
Sign In.
-
Перейдіть до Dashboards > Manage > Dashboards.
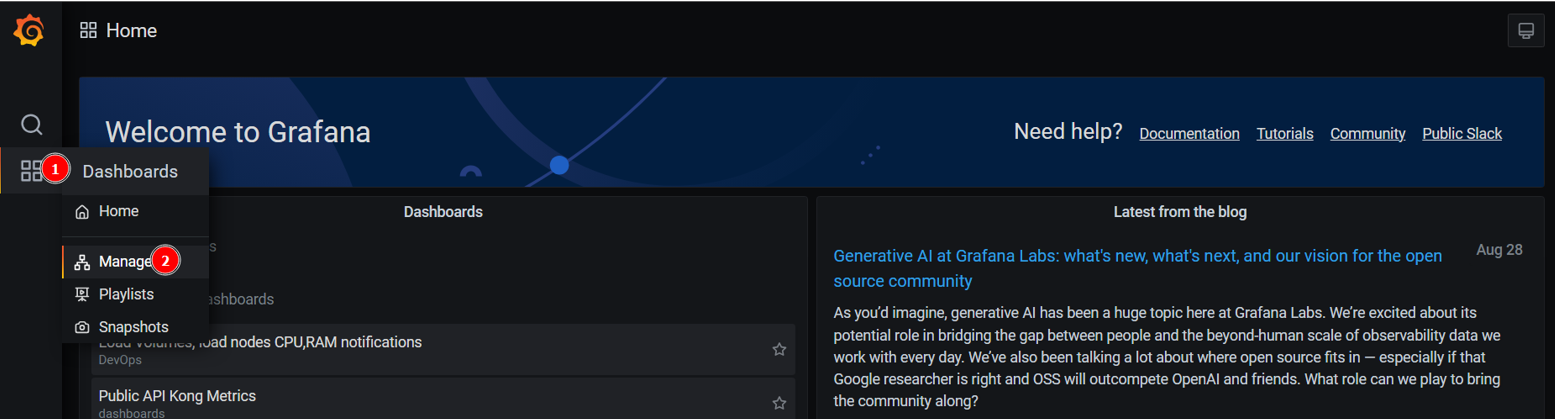
-
Ознайомтеся із наявними Dashboards.
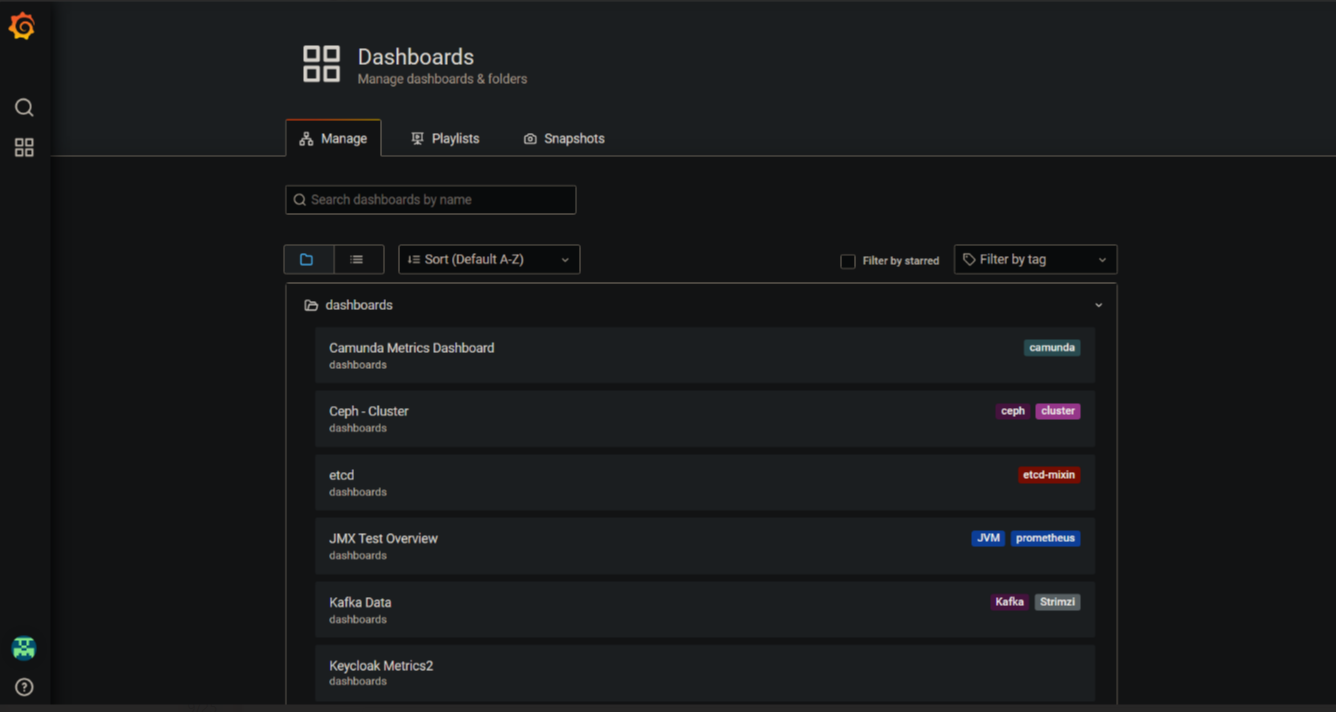
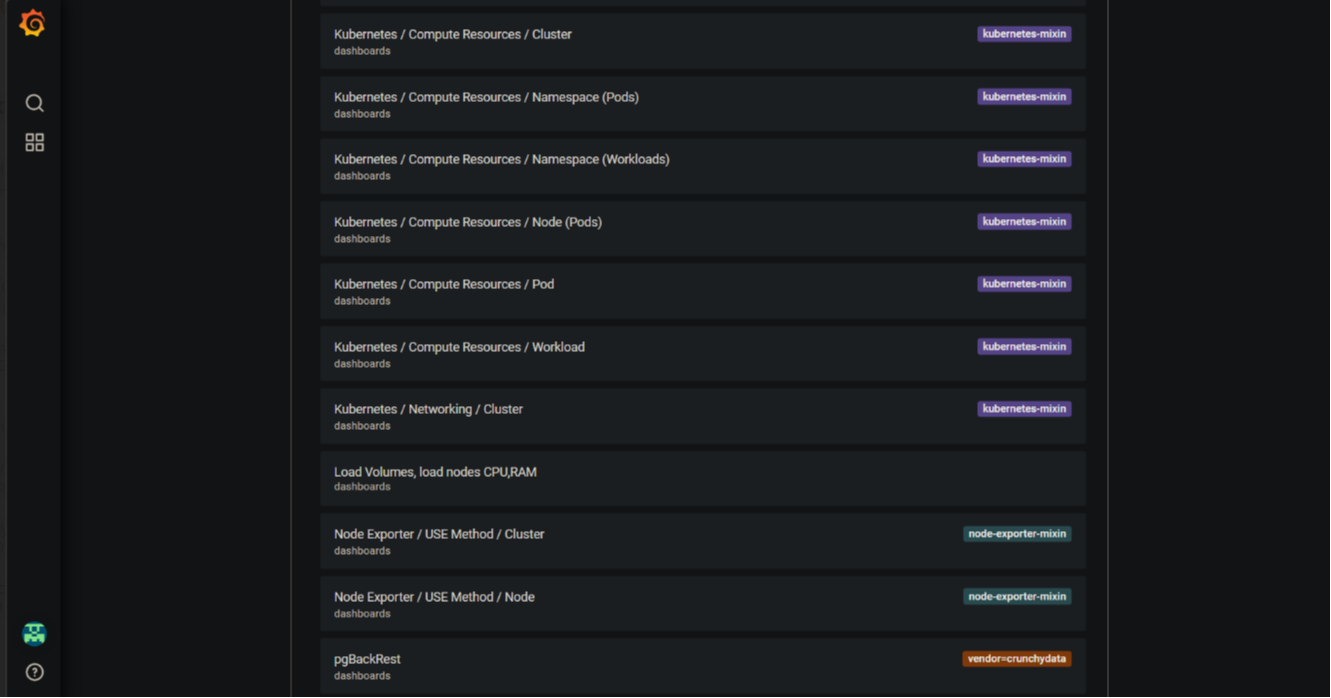
В рамках цього завдання буде розглянуто два дашборди із загального переліку. Інші пропонується дослідити самостійно.
2.2. Ознайомлення із дашбордом Spring Boot
-
Перейдіть до Dashboards > Manage > Dashboards > Spring Boot.
-
Оберіть
namespaceтестового реєстру та подbpms-xxxxxxxxxx-xxxxxxxxx.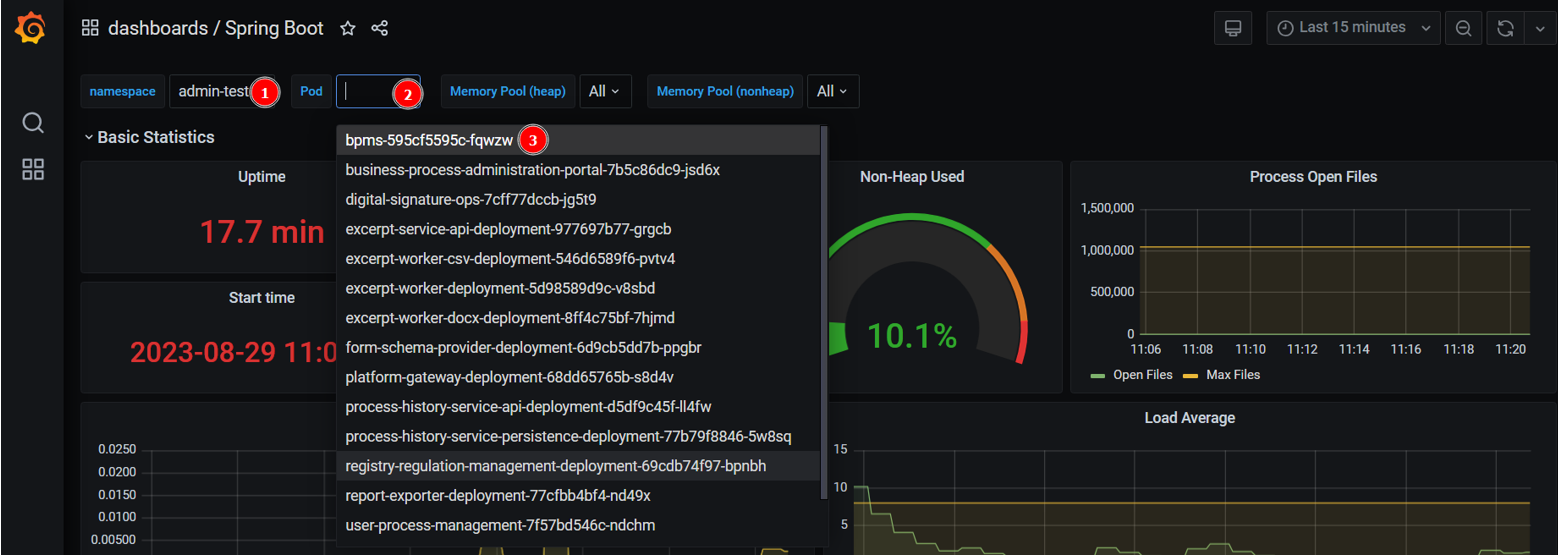
Тут ви зможете побачити метрики java, які знаходяться у контейнері із сервісом цього поду.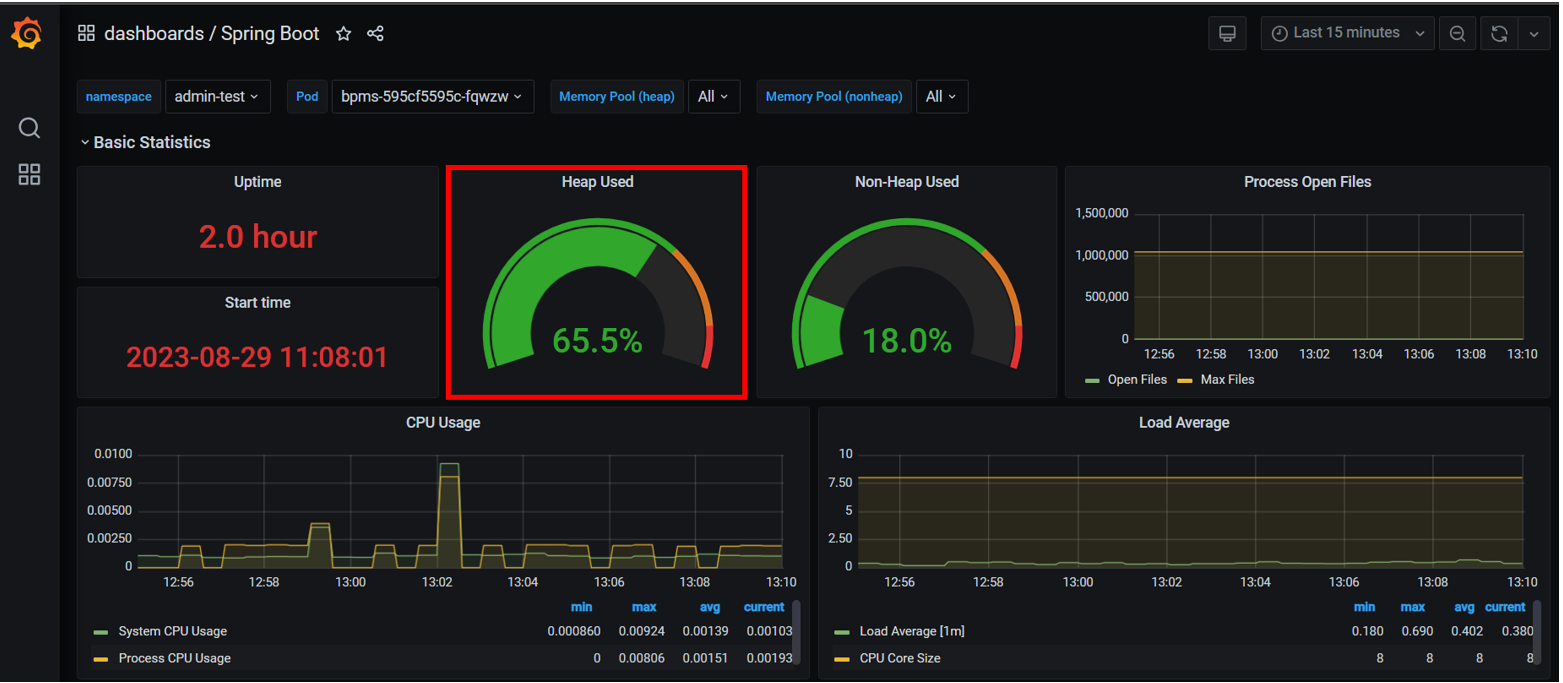
Зверніть увагу на показник
heap, це також може бути актуально і для розробників.
Heap— це ділянка пам’яті, яка використовується для зберігання об’єктів, які були створеніjava-застосунком. Його поділено на менші ділянки, які називаютьсяgenerations.Heapє значною частиною віртуальної машиниJava (JVM), і нею керує збирач сміття (garbage collector), який відповідає за автоматичне відновлення невикористаної пам’яті.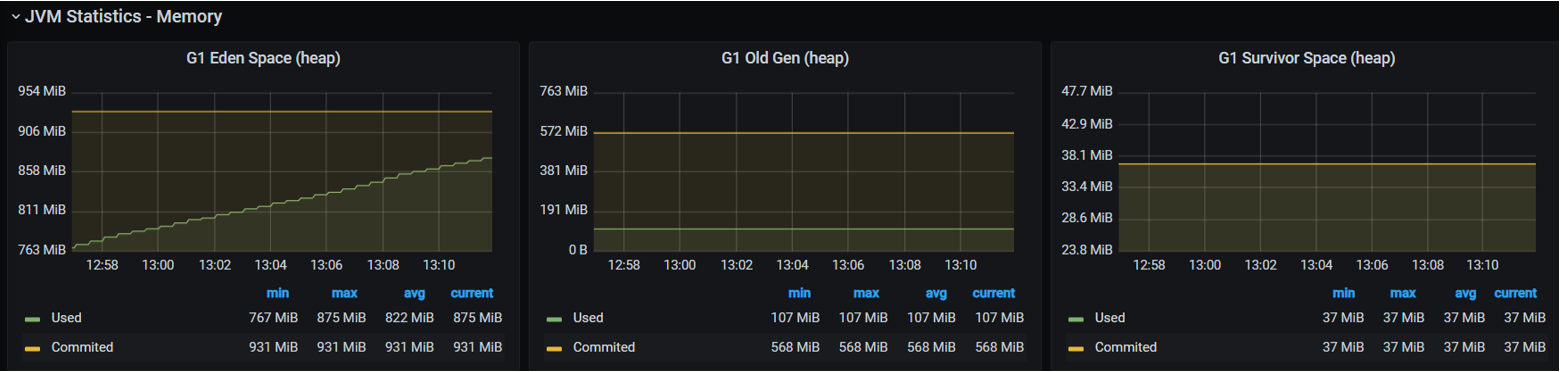
Якщо ви бачите, що використання heapзростає — це може бути приводом звернутися до розробників та повідомити, що є або витоки пам’яті, або проблеми ізgarbage collection.
2.3. Ознайомлення із дашбордом PostgreSQLDetails
-
Перейдіть до Dashboards > Manage > Dashboards > PostgreSQLDetails.
-
Оберіть операційний або аналітичний под тестового реєстру.
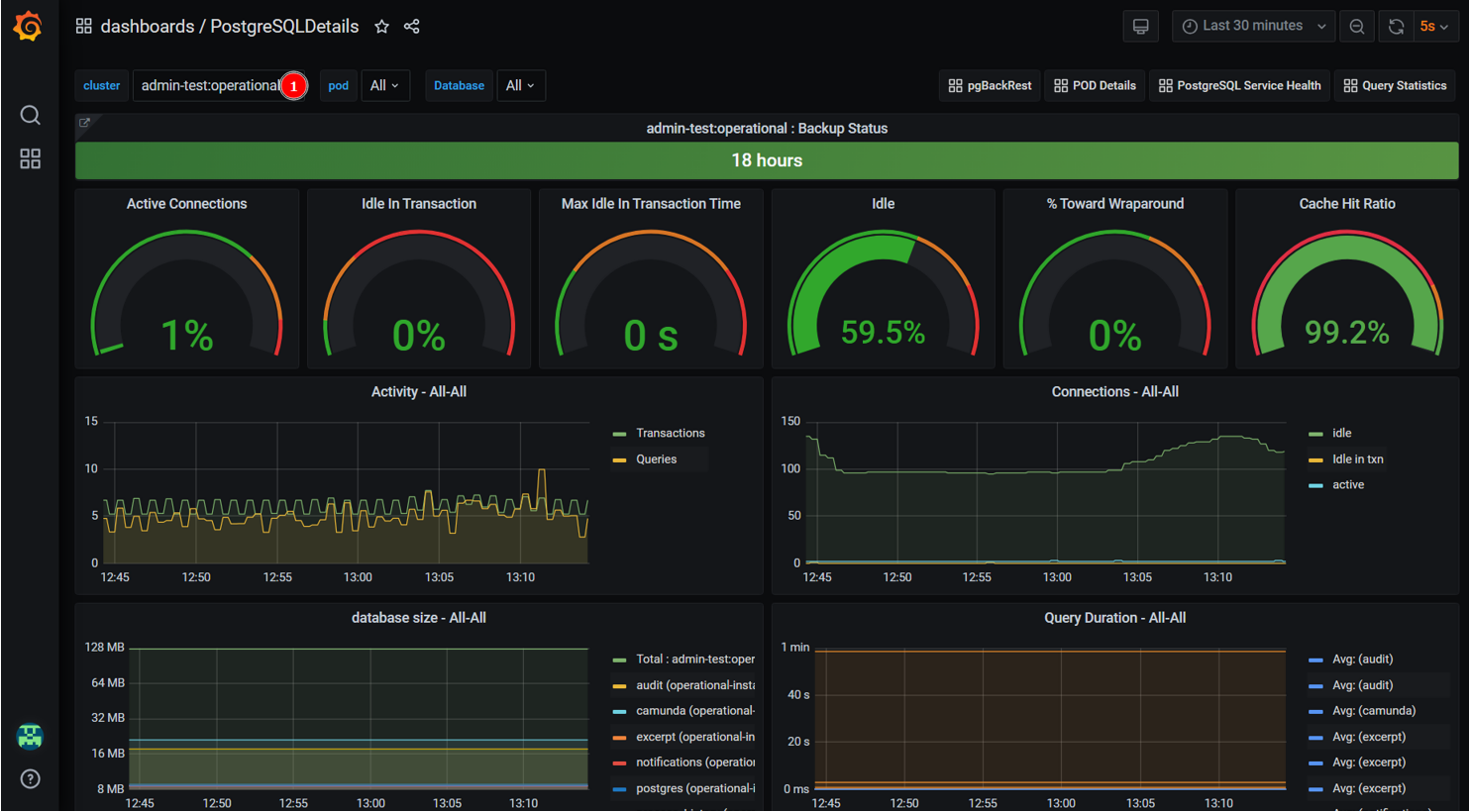
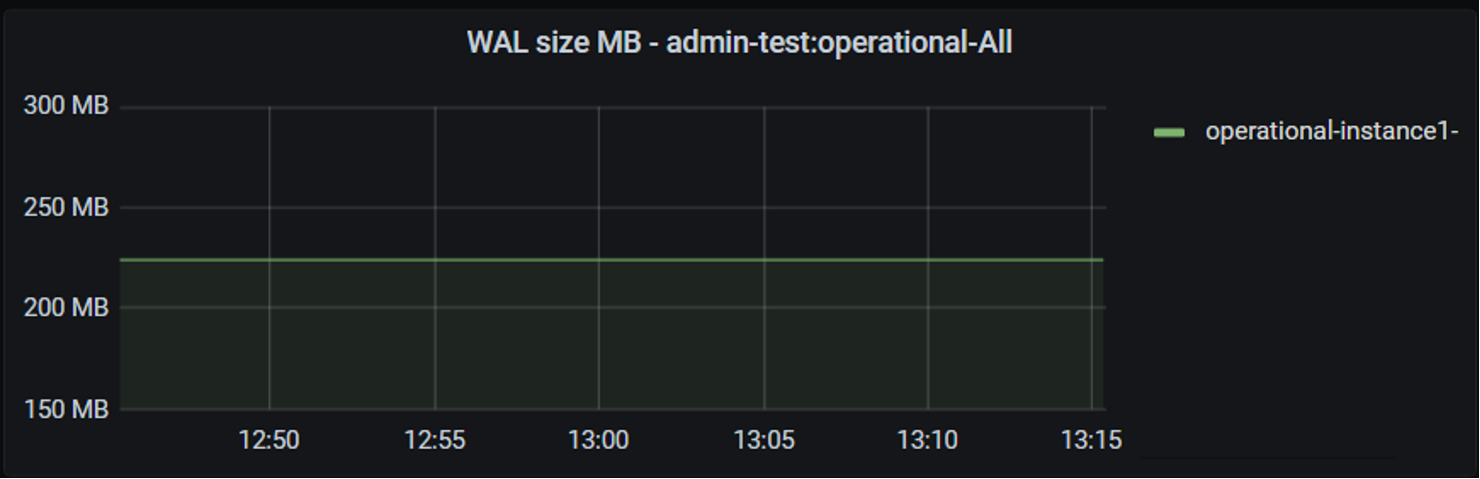
Зверніть увагу на показник
WAL.WALозначаєWrite Ahead Logging. Коли у базі даних відбувається зміна (наприклад, вставка, оновлення чи видалення), PostgreSQL спочатку записує зміну в логиWAL, які зберігаються в пам’яті та на диску.Логи
WALдопомагають відстежувати всі зміни, внесені в рамках транзакції, навіть до того, як вони будуть записані в основні файли даних.Основна мета
WAL-- забезпечити довговічність даних. Спочатку, реєструючи зміни в логах, PostgreSQL гарантує збереження даних у разі збоїв апаратного чи програмного забезпечення. Коли система відновлюється після збою, PostgreSQL може використовувати журналиWALдля повторного відтворення змін і відновлення бази даних до узгодженого стану.WALдозволяє PostgreSQL відкладати запис змінених даних до основних файлів даних, тим самим покращує продуктивність операцій запису. Операції запису зазвичай передбачають оновлення кількох файлів даних. Записуючи зміни доWAL, PostgreSQL може мінімізувати дисковий ввід-вивід і групувати кілька записів разом, тим самим підвищуючи загальну продуктивність запису.WALпотрібно перевіряти, тому що збільшення розміруWAL, може вказувати на зламану реплікацію, що може призвести до переповнення диска оперативного, а згодом й аналітичного екземпляра.